Welcome to Tech Mastery, your expert source for insights into technology and digital strategy. Explore topics like Adobe Experience Manager, AWS, Azure, generative AI, and advanced marketing strategies. Delve into MACH architecture, Jamstack, modern software practices, DevOps, and SEO. Our blog is ideal for tech professionals and enthusiasts eager to stay ahead in digital innovations, from Content Management to Digital Asset Management and beyond.
Most of the time, web developers struggle to understand the basics of DNS management, leading to confusion in their day-to-day operations. In this post, I want to discuss the DNS management basics that help Web Developers understand the DNS management process and help them in their daily operations. The screenshots and some of the steps captured here are based on the Cloudflare DNS manager.
What is DNS?
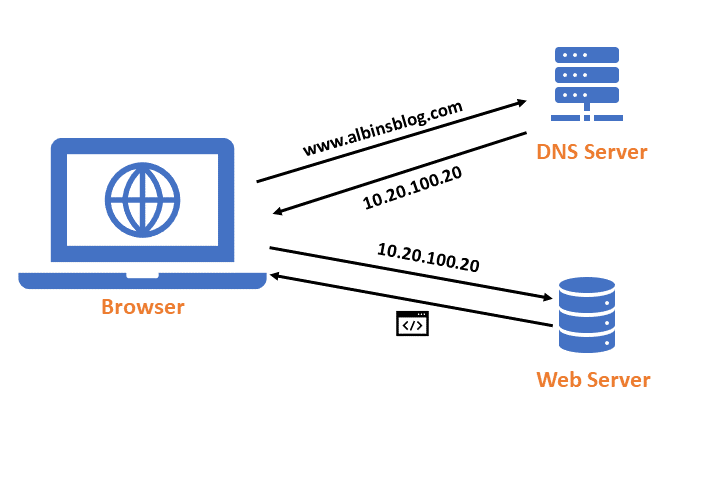
DNS stands for Domain Name System. The domain name system (DNS) is a naming database in which internet domain names are located and translated into Internet Protocol (IP) addresses. The domain name system maps the name people use to find a website to the IP address that a computer uses to locate that website.
For example, the DNS translates a web address like “www.albinsblog.com" into the physical IP address — such as”10.20.100.20" — of the computer hosting that site (in this case, www.albinsblog.com home page).
There are multiple Domain types( e.g., Generic Top-Level Domains (gTLD), Country Code Top-Level Domains (ccTLD) — not going to explain here), but as a web developer, we should be aware of the root/naked domain and the subdomains. When you register a domain name, you register what is known as the root domain, also called the naked domain, e.g., albinsblog.com is a root domain, you can register multiple subdomains under the root domain, e.g., www.albinsblog.com — here www is the subdomain on albinsblog.com root domain.
Domain Registrar:
A domain registrar is a business that sells domain names and handles the business of registering them, e.g., GoDaddy, Google, etc. All domain name registrars are accredited by ICANN (Internet Corporation for Assigned Names and Numbers), a non-profit organization responsible for managing domain names.
The domain registrar promptly updates and populates WHOIS(WHOIS is a database of information that allows users to look up domain and IP owner information and check out dozens of other statistics about the domain name) data to ensure the accuracy of the data.
DNS management:
DNS management is administering and managing the Domain Name System (DNS) for a particular domain or set of domains. It can include creating and editing DNS records, managing DNS zones, adding or deleting nameservers, and more.
What are Nameservers?
A nameserver is a server in the DNS management that translates domain names into IP addresses. Nameservers store and organize DNS records, each of which pairs a domain with one or more IP addresses.
Most Domain registrars will provide the default nameservers when registering a domain name. However, you can also use custom nameservers to manage the DNS records. Custom nameservers give you more control over your DNS settings and can be used to improve performance or security.
To use custom nameservers, you will need to set the “nameservers” for your domain to the DNS servers you want to use via your domain registrar’s control panel. Either use the registrar’s default name servers to manage the DNS records or point to custom nameservers through the registrar control panel so that the DNS records can be managed externally.
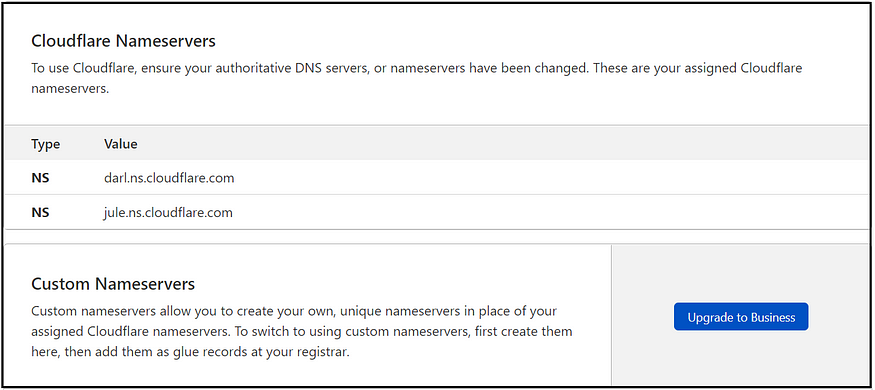
The DNS manager point to the default names servers, e.g., Cloudflare points to the default Cloudflare Nameservers; if required, the domain can point to the custom Nameservers.
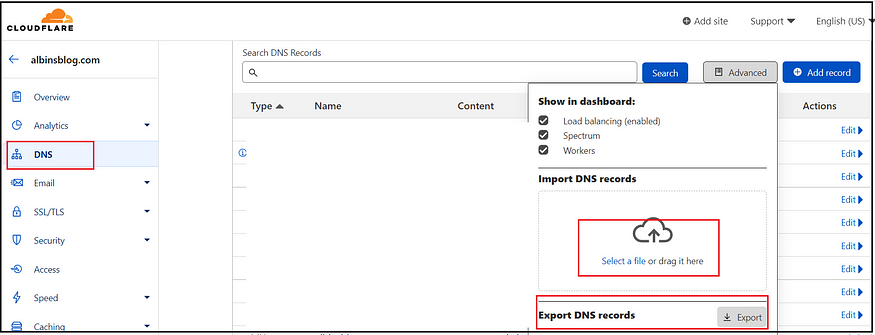
While pointing the existing DNS to a custom nameserver, the current DNS records can be exported as a Zone file, and the same can be imported to the custom name server.
A zone file is a primary location where all the DNS records are stored for the domain. Whenever someone performs a DNS query, the servers pull information from zone files to answer it.
The exported Zone file is a simple text file with all the configured DNS record details
example.com.txt
;; ;; Domain: example.com. ;; Exported: 2022-09-28 23:47:34 ;; ;; This file is intended for use for informational and archival ;; purposes ONLY and MUST be edited before use on a production ;; DNS server. In particular, you must: ;; -- update the SOA record with the correct authoritative name server ;; -- update the SOA record with the contact e-mail address information ;; -- update the NS record(s) with the authoritative name servers for this domain. ;; ;; For further information, please consult the BIND documentation ;; located on the following website: ;; ;; http://www.isc.org/ ;; ;; And RFC 1035: ;; ;; http://www.ietf.org/rfc/rfc1035.txt ;; ;; Please note that we do NOT offer technical support for any use ;; of this zone data, the BIND name server, or any other third-party ;; DNS software. ;; ;; Use at your own risk. ;; SOA Record example.com 3600 IN SOA example.com root.example.com xxxxxxx xxxx xxxx xxxxx xxxx;; A Records example.com. 1 IN A 10.20.100.20;; CNAME Records www.example.com. 1 IN CNAME test.cdn.com.;; MX Records example.com. 3600 IN MX 5 gmr-smtp-in.l.google.com.;; TXT Records example.com. 1 IN TXT "v=spf1 include:_spf.google.com ~all" www.example.com. 1 IN TXT "yandex-verification: xxxxxxxxxxxxx"
DNS Records:
DNS records are instructions created and stored in a Zone File on DNS servers. These records provide essential and relevant details about domains and hostnames. These records also contain various commands on how DNS servers must handle DNS requests.
The DNS Manager provides the portal to manage the DNS records for a Domain.
DNS Record Types commonly used:
A-Record — Most commonly used to map a fully qualified domain name (FQDN) to an IPv4 address and acts as a translator by converting domain names(e.g., www.albinsblog.com) to IP addresses(e.g., 10.20.100.20).
The mapping can be enabled for the root domain (e.g., albinsblog.com — referred to as @) or different subdomains(e.g., www.albinsblog.com, test.albinsblog.com)
AAAA — AAAA records resolve a domain name corresponding to an IPv6 address.
CNAME — CNAME records can be used to alias one name to another. CNAME stands for Canonical Name.
For example, albinsblog.com and www.albinsblog.com point to the same application and are hosted by the same server. To avoid maintaining two different A-Records records, it’s common to create:
An A record for albinsblog.com pointing to the server IP address
A CNAME record for www.albinsblog.com pointing to albinsblog.com
Another case is; if the subdomain needs to point to a server that is enabled with dynamic IPs or multiple IPs, e.g., CDNs; in this case, it makes sense to enable a CNAME record pointing to a domain that intern points to the required IPs.
A CNAME record cannot co-exist with another record for the same name. It’s impossible to have a CNAME and TXT record for www.albinsblog.com.
The default behavior is the Top/Root domains, e.g., albinsblog.com can’t be pointed to the CNAME record but only to A-record.
While you are hosting a website through an external CDN that requires CNAME pointing — the main website will be hosted on a subdomain, e.g., www.albinsblog.com(www CNAME pointing to the CDN Domain), and the Top Domain should point to a server/service through A-Record (IP Address). The server/service can redirect the top domain to the subdomain(albinsblog.com to www.albinsblog.com); most of the time, the DNS manager provides the Forwarding service to redirect the root or specific subdomain to a specific target URL.
The recent concept — of CNAME flattening is supported by some of the DNS managers, e.g., Cloudflare allows us to enable the CNAME record for top/root domains.
Also, another nonstandard record type, ANAME(also called ALIAS, Virtual record type),supported by some of the DNS providers, e.g., GoDaddy, Google Domain, etc., provides CNAME-like behavior for apex (root) domains — point to the root domain to a DNS.
TXT Record- TXT records are a type of DNS record containing text information for sources outside your domain. The TXT records can be used for various purposes, e.g., Verify domain ownership for SSL cert Generation, Verify domain ownership for Google Analytics, Verify domain ownership for SEO tools, etc.
The SPF(Sender Policy Framework) records are a type of DNS TXT record commonly used for email authentication. SPF records include a list of IP addresses and domains authorized to send emails from that domain.
SOA — The DNS ‘start of authority (SOA) record stores essential information about a domain or zone, such as the administrator’s email address, when the domain was last updated, and how long the server should wait between refreshes. All DNS zones need an SOA record to conform to IETF standards. The DNS manager, by default, enables the SOA record for the domain.
MX — A DNS ‘mail exchange’ (MX) record directs email to a mail server. The MX record indicates how the Simple Mail Transfer Protocol should route email messages. Like CNAME records, an MX record must always point to another domain. You can define multiple MX records for a Domain; the priority number indicates the preference.
DNS Propagation:
DNS propagation is the time period in which it takes updates to DNS records to be in full effect across all servers on the web. Changes aren’t instantaneous because nameservers store domain record information in their cache for a certain amount of time before they refresh.
Typically DNS propagates within a few hours, though it can take as long as 72. The timeframe for propagation depends on several factors, including your internet service provider (ISP), your domain’s registry, and the TTL(Time to Live) values of your DNS records.
High TTL values are typically used for records that rarely change, such as MX or TXT. A high TTL provides faster responses for more static resources by storing the information locally before retrieving it again.
The Records that need frequent updates require a low TTL value. Low TTLs are recommended for critical records and are changed frequently. A good range would range from 30 to 300 seconds (5 minutes).
While modifying the critical DNS records, proper planning may require to avoid the downtimes for the end users — if the record is already enabled with high TTL better to change the TTL to a low value as a first step ahead of actual change; some users will still be served a cached version of your site until all servers have propagated.
You can use any DNS checker tool, e.g., DNS Checker — DNS Check Propagation Tool, DNS Checker — DNS Check Propagation Tool, to verify the DNS propagation status across different locations.
DNS Transfer to New Registrar:
Sometimes we may need to transfer our domains to a different registrar; domain transfer is switching your domain name from one registrar to another. To be eligible for a transfer, you must have been with your current registrar for at least 60 days since ICANN enforces a 60-day Change of Registrant lock.
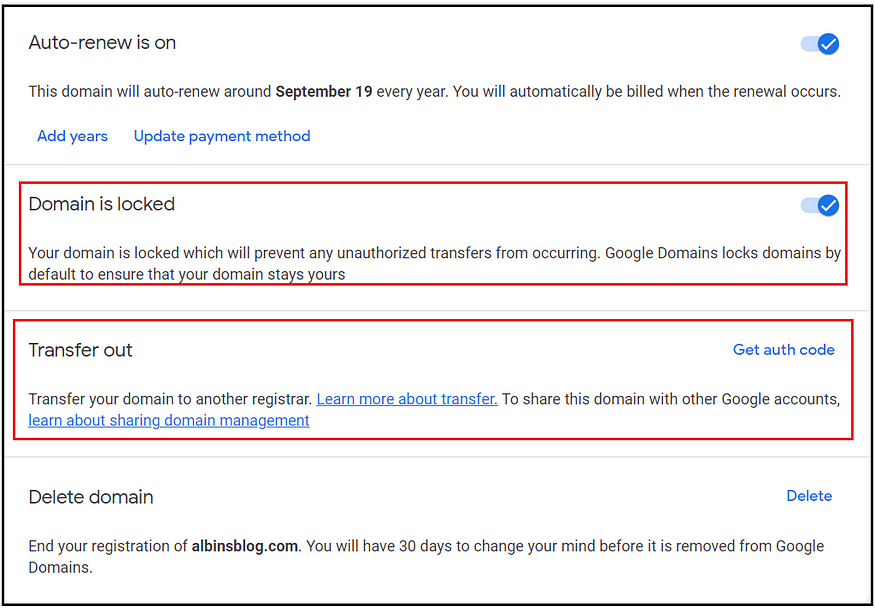
Once you finalize the transfer, the domain should be unlocked from the current registrar to initiate the transfer — the DNS manager supports this configuration through the portal; generate the transfer AUTH token from the current registrar. The new registrar can initiate the transfer through the AUTH token.
Google Domains
The DNS records from the existing registrar will be migrated to the new registrar; may need to pay special attention if the Domain is using the default name server enabled by the current registrar — the names server pointing should be changed to a new registrar default names servers post transfer. Additionally, ensure the new registrar supports the special services(e.g., domain forwarding) supported by the current registrar.
DNS Security:
Enabling the required DNS security helps to protect the DNS from security attacks, e.g., DNS spoofing/Cache Poisoning, DNS Hijacking
DNS Over HTTPS(TLS) — DNS queries are sent in plaintext, which means anyone can read them. DNS over HTTPS and DNS over TLS encrypts DNS queries and responses to keep user browsing secure and private. For more details, refer to DNS over TLS vs. DNS over HTTPS | Secure DNS | Cloudflare DNS over TLS vs. DNS over HTTPS | Secure DNS | Cloudflare for more information.
DNSSEC — The DNS system is not initially built considering the security; DNSSEC strengthens authentication in DNS using digital signatures based on public key cryptography. With DNSSEC, it’s not DNS queries and responses that are cryptographically signed; instead, the data owner signs DNS data itself. This is critical to protect the important domains through DNSSEC to avoid security attacks. Refer to How DNSSEC Works | Cloudflare for more details on DNSSEC.
Domain Lock — As discussed earlier. domain lock will prevent any unauthorized transfers from occurring
Tools:
Some of the tools that will help us while working with DNS
nslookup/dig — command-line tools for querying the Domain Name System (DNS) to obtain the mapping between a domain name and IP address or other DNS records.
In this post, I will explain my experience integrating the Coveo Search platform with the AEM platform based on my experience migrating Adobe Search & Promote to the Coveo platform.
Coveo is a software-as-a-service search engine powered by artificial intelligence. Refer to the following document for more details on the Coveo Platform — Coveo Overview.
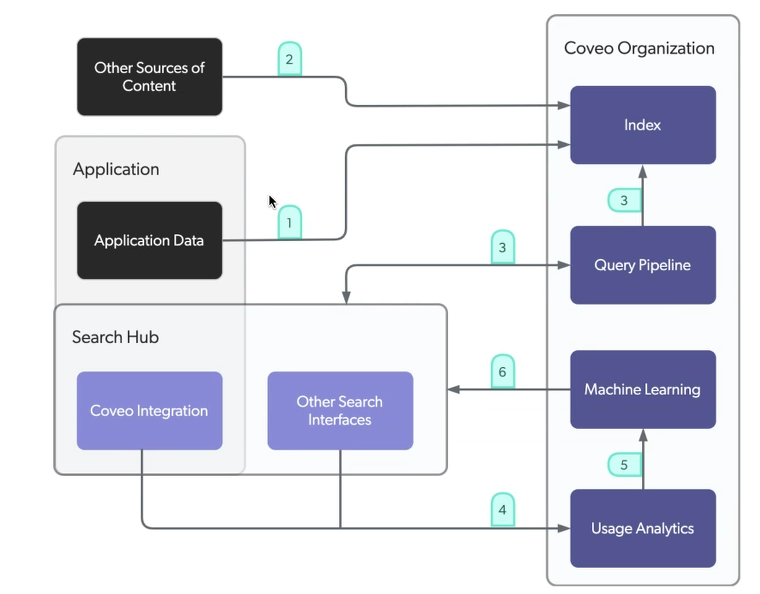
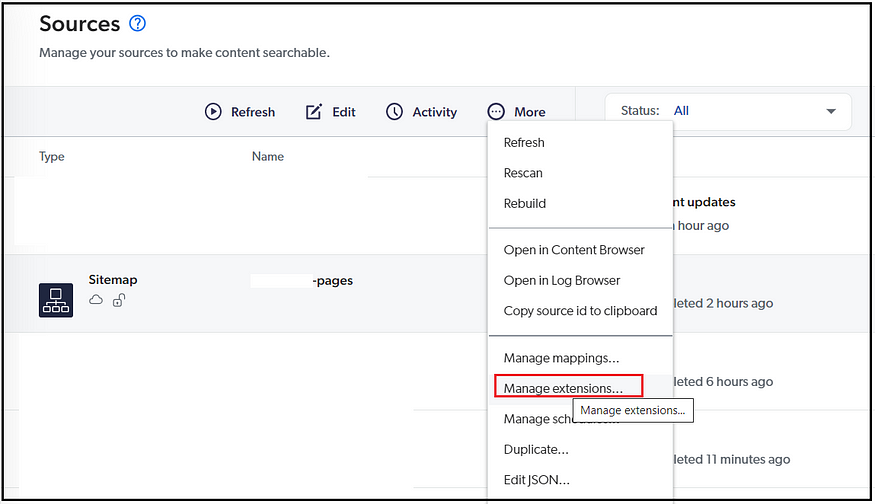
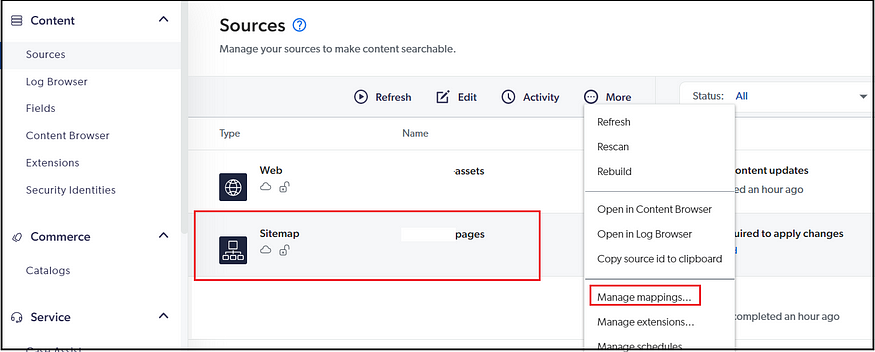
Setting Up the Sources:
A source is a connector configuration and an index container that holds all of the items related to a repository, e.g., Web, Sitemap, Youtube, etc.
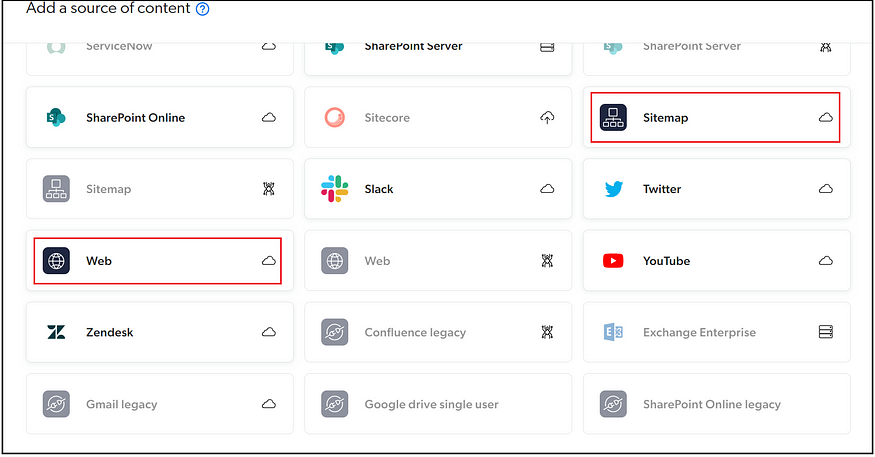
AEM connector is more flexible to configure and easy to manage; in my perspective, if your AEM content is organized correctly, the AEM Connector makes sense to enable the indexing. In case you are migrating the existing website, you don't want to make a significant change to the current indexing process, the other Coveo connectors like Sitemap(use the website sitemap to index the content) and Web(more to crawl and index the pages and assets — mainly used for indexing assets, e.g., PDF, the PDF's can even be indexed through Asset Sitemap enabled in AEM). Please note that AEM Connector is still in development, and AEM as a Cloud Service Support needs to be reviewed.
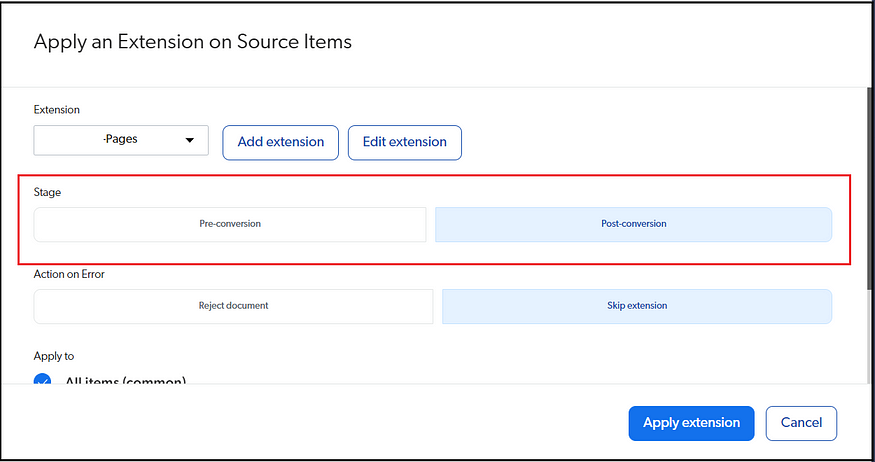
You can use the other available connectors to index the content from any other sources; a Generic REST API connector can be used to pull the content through a standard REST API endpoint supported sources. You can enable optical character recognition configurations to allow the index of text within the image and pdfs.
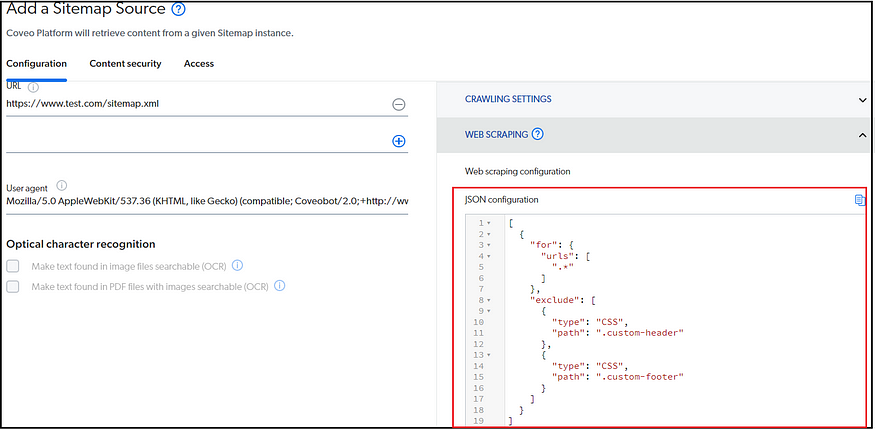
Web and Sitemap sources can include a web scraping configuration to control the content getting indexed; refer to Web Scraping Configuration (coveo.com) for more details on web scraping. For example, exclude the header and footer content from indexing, specify the configuration as a JSON
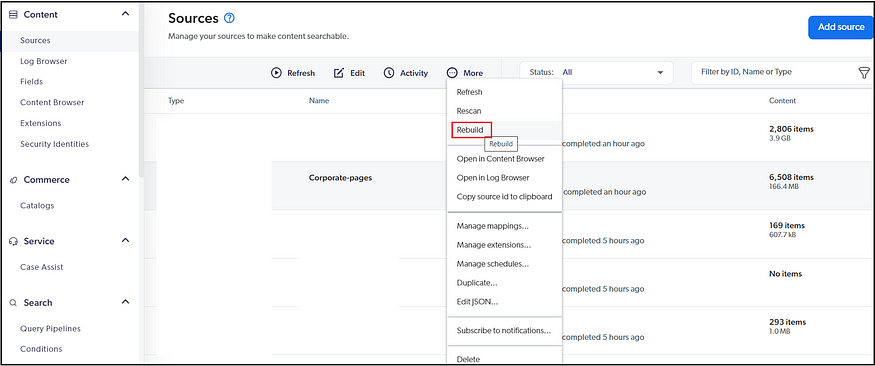
You should rebuild the source to reflect those changes whenever the source configuration is modified, e.g., Sitemap URL, Fields, etc.
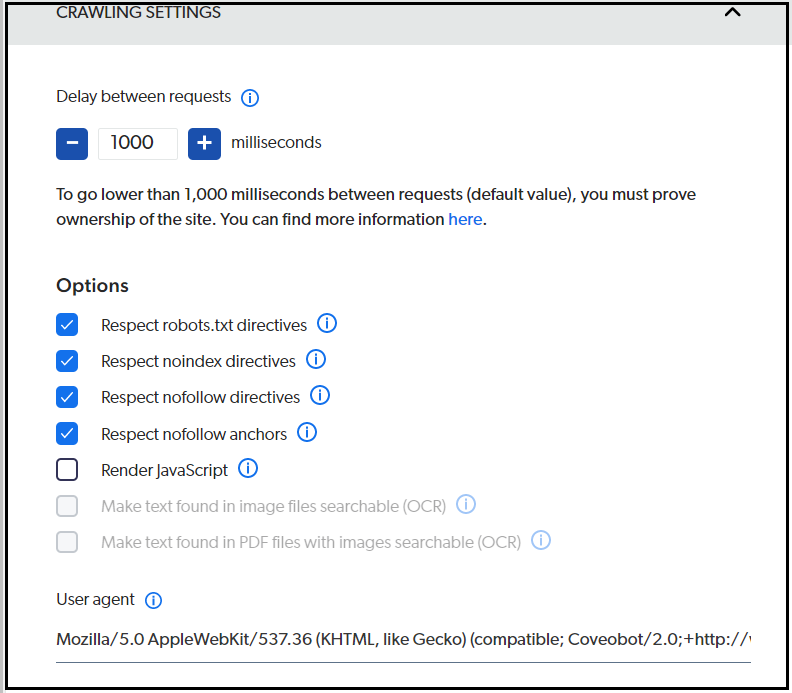
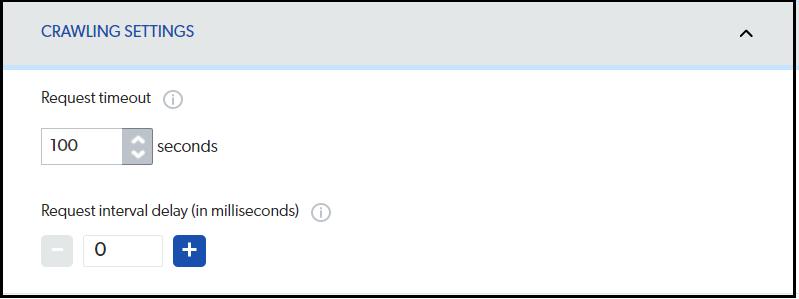
Crawl settings can be enabled if required
Web Source
Sitemap Source
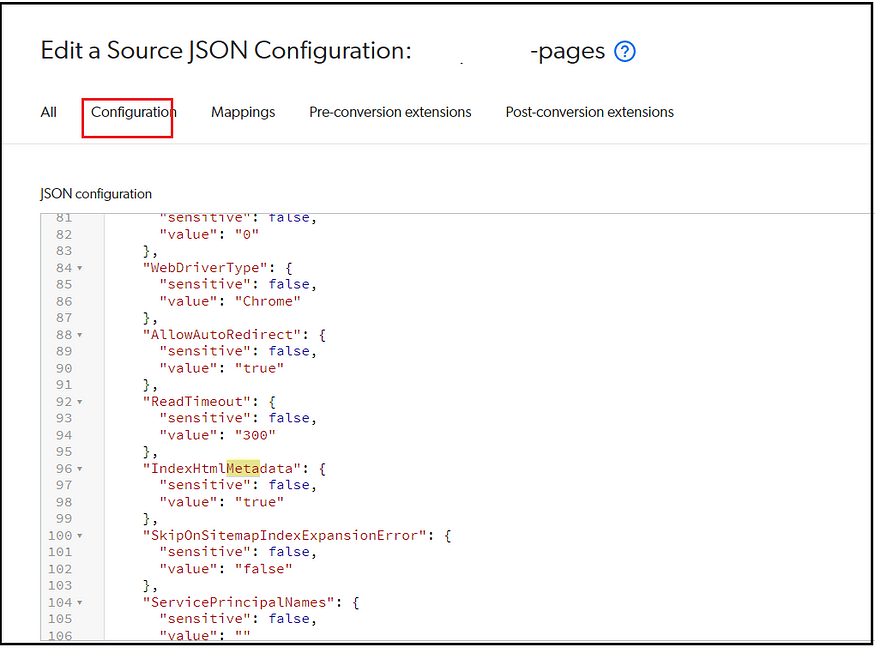
Some of the hidden configurations can be directly enabled by editing the JSON.
e.g., IndexHtmlMetadata for Sitemap Source; by default, the HTML metadata is not indexed; modify the value to “true” to index the HTML metadata for the required sitemap resources.
For example, if you want to identify the language/country based on the URL and add the required metadata to the item or change date values or reject items that don't meet criteria or change an item body, or enable the facets with minimal available data, etc.
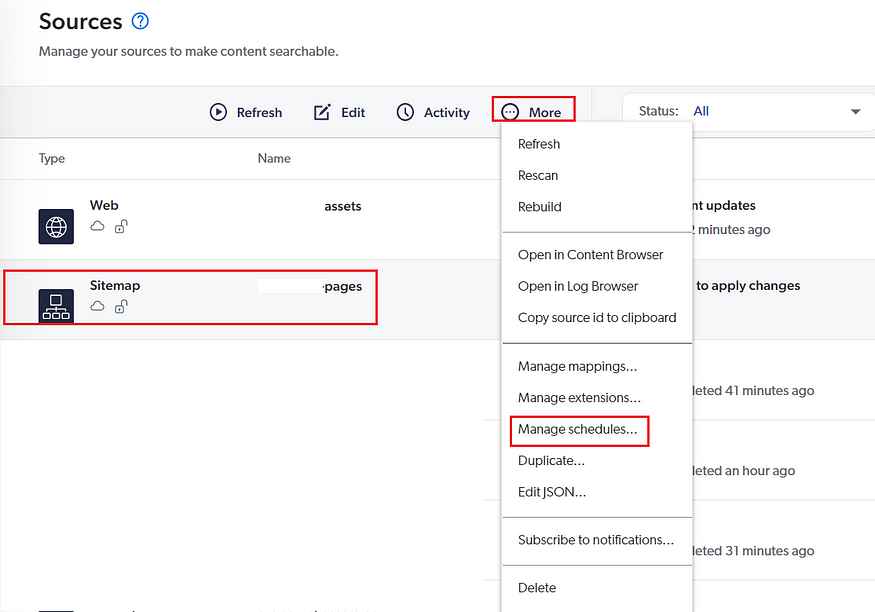
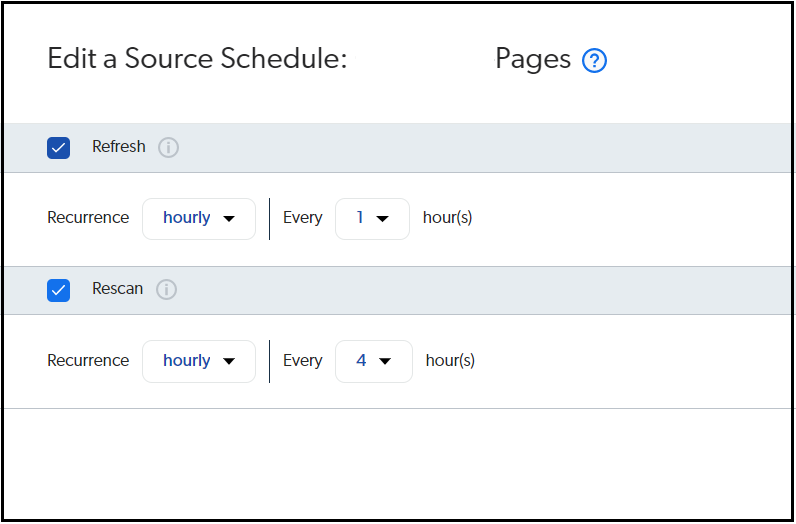
The source can be scheduled to index the content at specific intervals.
Refresh — During a refresh operation, Coveo crawls the items and permission models identified by your content system as modified since the last source update. Then, Coveo retrieves the changes and updates your index—refresh factor in only the modified content.
Rescan — During a rescan operation, Coveo crawls all items in your content system. Rescan factor in Add/Delete/Modified Content.
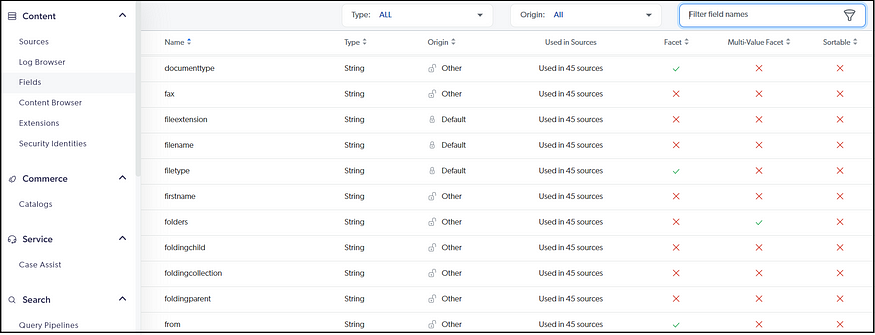
Fields:
Define the list of custom metadata fields applicable for all the sources.
The Fields can be marked as a Facet/Multi-Value Facet or Sortable based on the business requirement. The supported Fields for the individual sources can be mapped at the Source level.
Map out the Fields to the actual metadata available in the source.
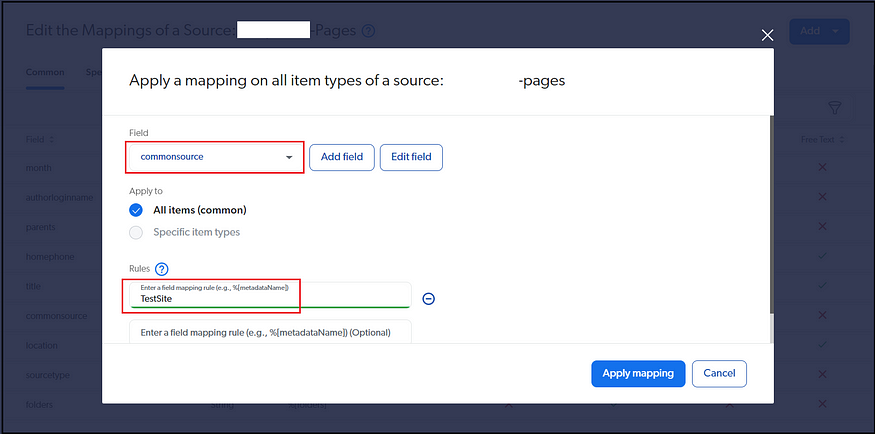
You can enable a custom field, e.g., commonsource, with source-specific value to support multiple search interfaces(sites) that display the data from specific sources; the Filtering logic can be enabled in the Query Pipeline.
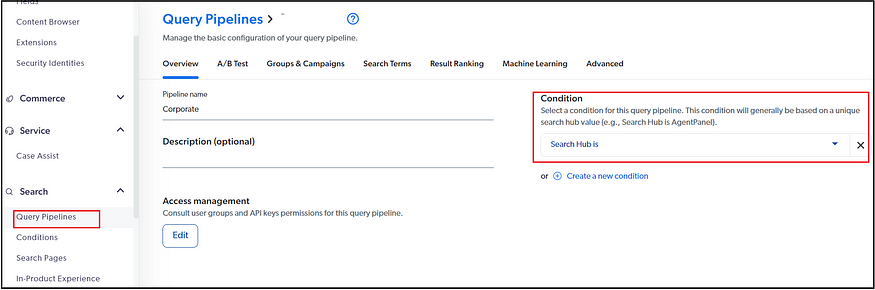
Conditions:
A query pipeline condition is a set of predefined requirements that a query must meet to go through a query pipeline or trigger the execution of a query pipeline statement. A query pipeline condition is a set of predefined requirements that a query must meet to go through a query pipeline or trigger the execution of a query pipeline statement. Each query pipeline and query pipeline rule/ML model association can only be associated with a single condition.
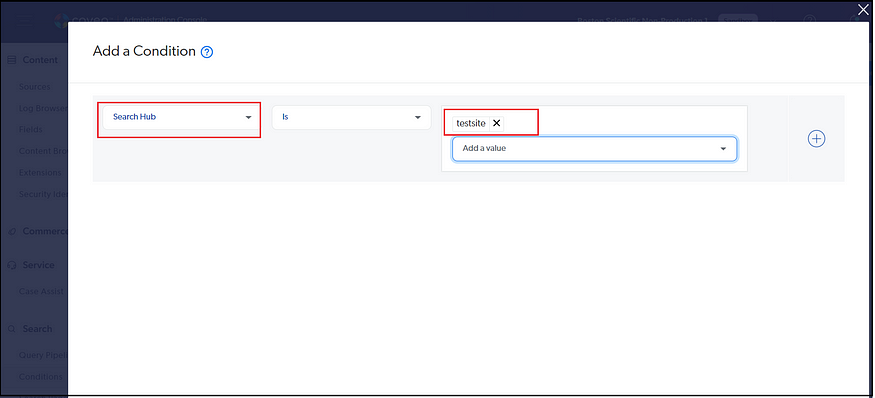
You can add the condition based on different parameters, such as a minimal Search Hub to associate a specific pipeline with the website — the search hub will be passed as a parameter while fetching the search result from the website(Search Hub is a Search API query parameter whose value is a descriptive name of the search interface from which the query originates. This lets you create an optimized query pipeline for a specific search interface.)
Configure Query Pipeline:
You can define query pipelines in your Coveo organization when you have more than one search interface(Search Hub) with distinct users and purposes, and you want to apply different rules or models for each search interface.
You can associate a condition created in the earlier step to associate the query pipeline with specific scenarios, e.g., Search Hub(Search Interface)
You can also define
A/B tests:
Campaigns:
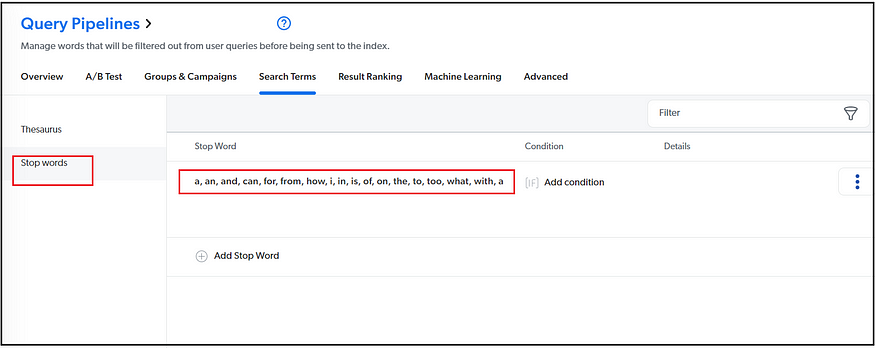
Search Terms: (Thesaurus rules— define synonyms and Stop words and Stop words — words that are filtered out from a query entered by an end user before it's sent to the index)
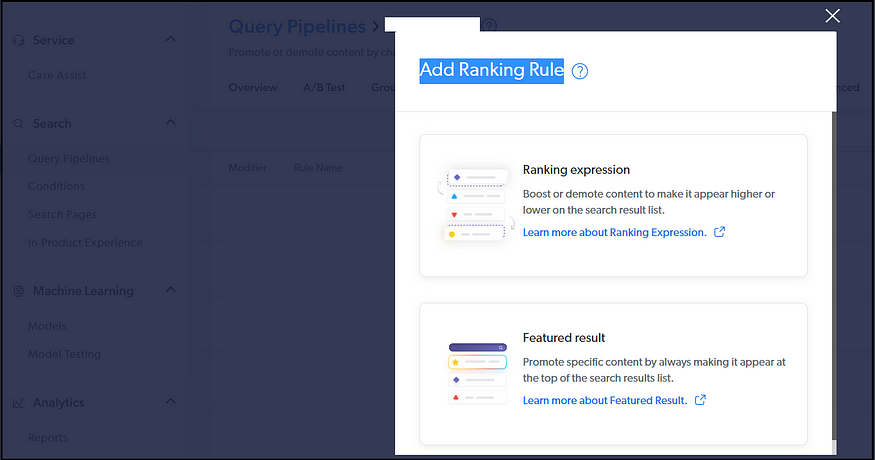
Result Ranking — You can change the ranking score of the content or display specific content as featured content.
Associate the Machine Learning Models
Advanced — you can define some advanced configurations like
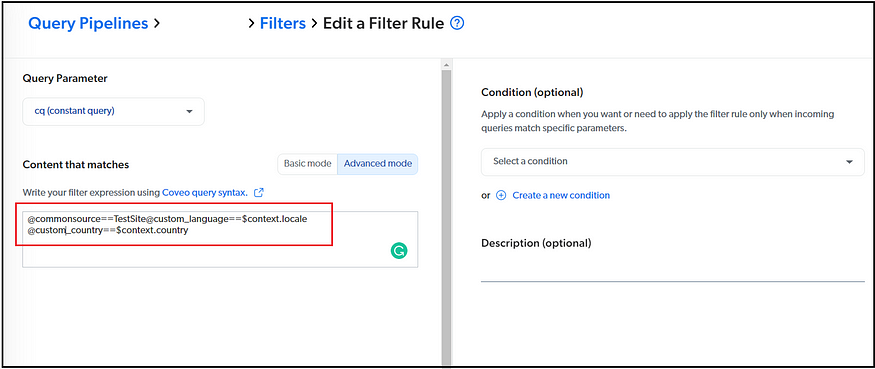
Filters — to define the scope of the search, e.g., enable country code and language code as a filter to support multi-country and multi-language sites(no need to define multi-sources to support this use case — instead, use Filter along with context data from search interface to scope the search result). Also, the scope can be restricted based on the Field defined in the source, e.g., commonsource.
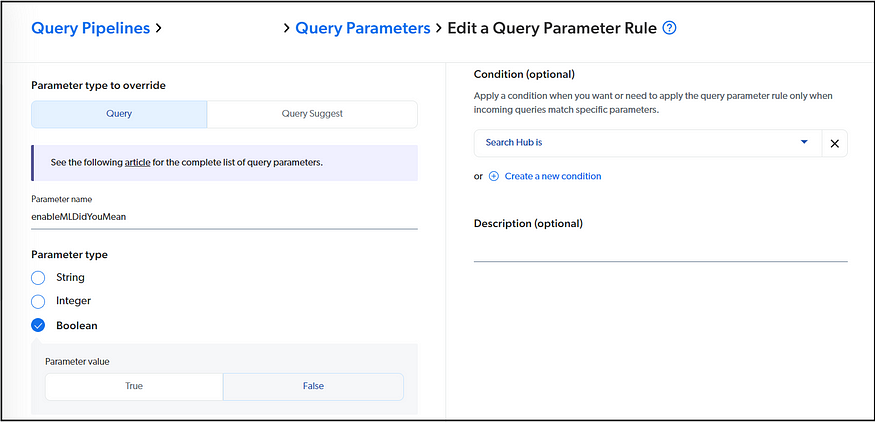
Query Parameters Rules — You can configure query parameter rules to override the default query parameters when a certain condition is met. e.g. enable or disable enableMLDidYouMean/enableDidYouMean based on specific condition.
Ranking Weights — The Coveo Platform index uses default ranking factors to evaluate the relevance score of each search result for each query. When you see that the ranking of specific search results isn't ideal in a particular context of search or case, you can adjust the value of one or more ranking factors.
Triggers — You can configure Notify, Query, Execute, and Redirect triggers to execute actions in your search interfaces when a specific query is performed.
Coveo JavaScript Search Framework — This open-source, component-based framework allows developers to easily customize and deploy feature-rich, client-side search interfaces on any web page, site, or application.
We used Coveo Search UI(Coveo JavaScript Search Framework) to build our search interfaces considering the project timeline and effort; you can create multiple search interfaces to support your business needs, e.g., support different themes, fonts, structures, etc. The JavaScript Framework is enabled with various OOTB components, but custom/extended components can be enabled based on your business need.
Enable the Search interface with required components, e.g., Pagination/Facets/Sorting/Filters/Search Suggestions, AutoComplete, etc., and the look and feel. You can add the search interface-specific context data to the search UI; the context data can be used in Query Pipeline Filter to restrict the data specific to the scenario, e.g., filter the data based on country and language for multi-country/language websites.
//identify the language and country based on the URL pattern and set it as a context variable.Coveo.$$(document.getElementById('coveo-search')).on('buildingQuery', function(e, args) {args.queryBuilder.addContextValue('country', country);args.queryBuilder.addContextValue('locale', locale);});
The page metadata is another critical factor in enabling the facets; if possible, tag the AEM pages with different metadata that can be used as a facet.
You can host the i18n key updates into AEM, maybe as a client library path, e.g./etc.clientlibs/project/clientlibs/assets/resources/i18n/search.coveo.js.
So easy to manage in the future; also, the CSS file can be enabled through AEM as a client library path(inline CSS is not recommended) e.g.,/etc.clientlibs/project/clientlibs/assets/resources/css/sitea/search.coveo.css
Ensure the accessibility is factored in during the development and testing of the search interfaces.
The search interface can be integrated into AEM through Coveo Hosted Search Page Component.
Install the package in author and publisher instances.
Enable the hosted search page component to the required templates.
Add the hosted search page component to the search-result pages.
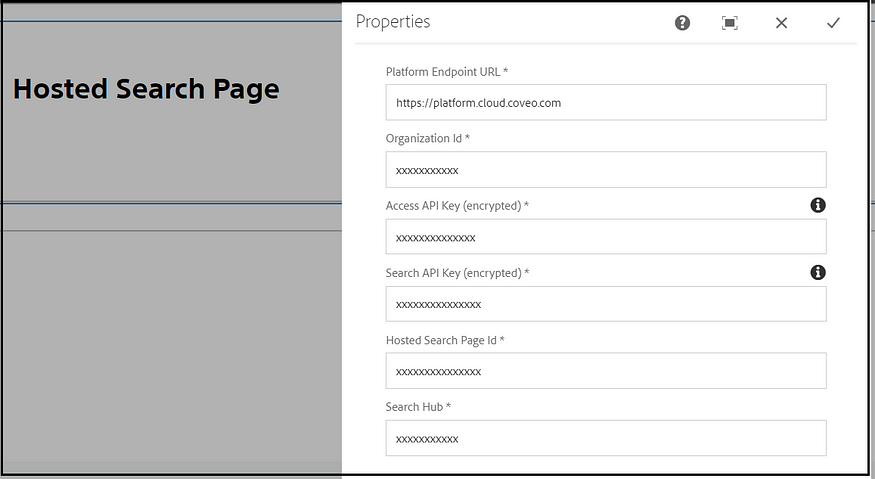
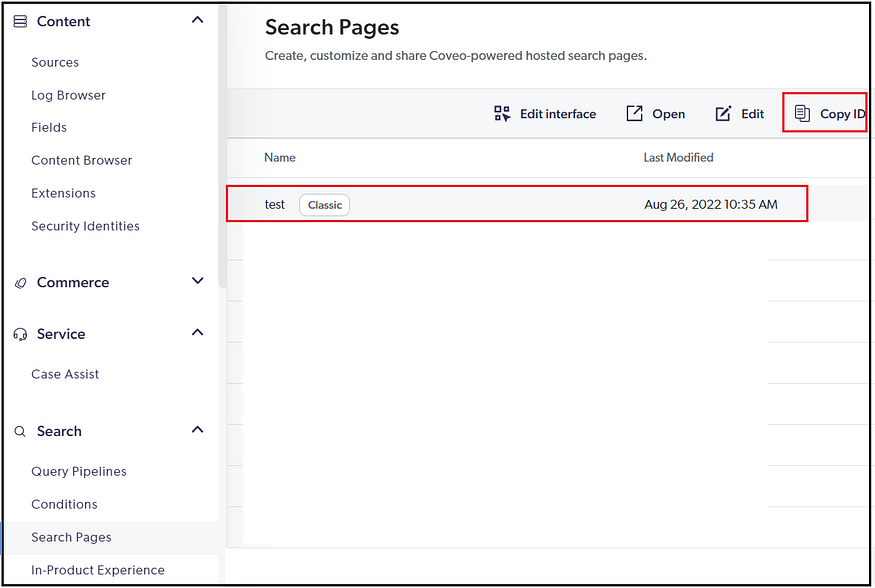
Configure Coveo organization ID(In most implementations, will have two organizations — Non-Prod and Prod), Search page ID, API keys for access and search, Search Hub, and platform endpoint URL
You can copy the Id of the search page.
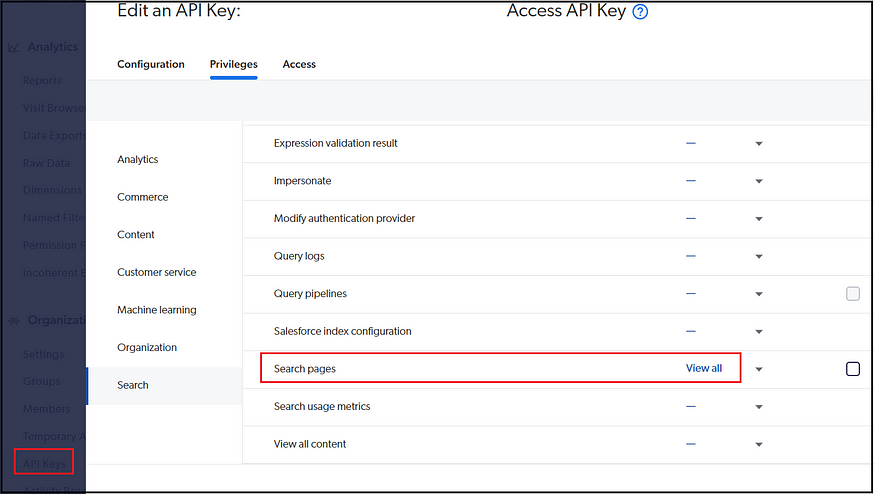
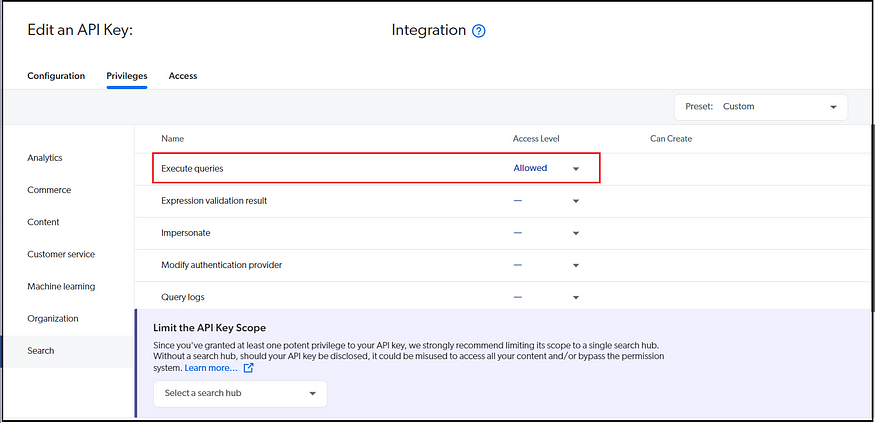
Enable Access and Search API Keys with required access
Now the search results are displayed on the result page; activate the page to the publisher.
The search interfaces will send the Search Page name as the Search hub (coveo.com) as part of the API request to fetch the search results; the Search Hub value can be used in Query Pipelines/Conditions to restrict the section of data that is specific to an interface. The SearchHub value can be used as part of the APIs to fetch the particular data section.
The search box on the header:
You can follow the Create a Standalone Search Box (coveo.com) approach to enable the Search box on the page headers; modify the search hub value in the HTML based on your configuration
Suppose, if required custom search box can be enabled on the header and Query Suggest API to display the suggestion but enabling the Coveo standalone search box makes more sense in the long run. In that case, the standalone search box will have the inbuilt query suggest also extended by adding additional components, e.g., recommendations. You should configure the Coveo token(make this configurable in AEM and inject it into the pages through a hidden field) and the search result URL. Also, you should include the required Coveo CSS and JS as part of the site client Library. Refer to JavaScript Search Framework Events (coveo.com) to attach to the specific events to enable any custom functionalities, e.g., disable the search box until the user types in 3 characters.
Create an access token with limited access to support the header search box functionalities, e.g., query suggest
Users will be directed to the configured search result page while clicking on a search term or a search button.
Machine Learning:
Coveo Machine Learning (Coveo ML) models are algorithms that leverage usage analytics data to provide contextually relevant recommendations to the users. Multiple OOTB ML models are available; refer to Machine Learning Overview (coveo.com) for more details; Custom models can be enabled if your team can support that.
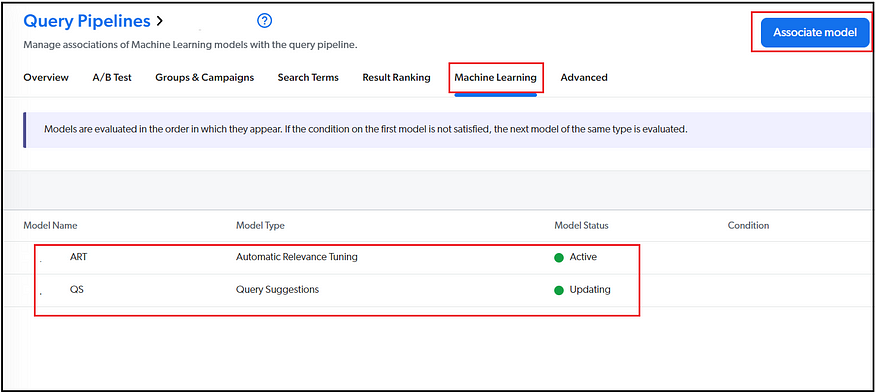
You can create the model specific to your scenarios(e.g., Site Specific) and associate it with the Query Pipeline.
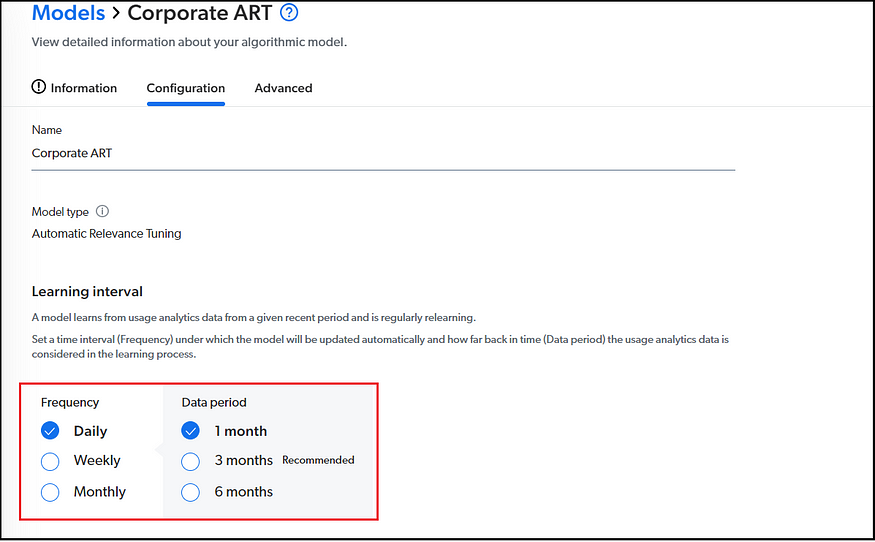
Configure the Learning interval
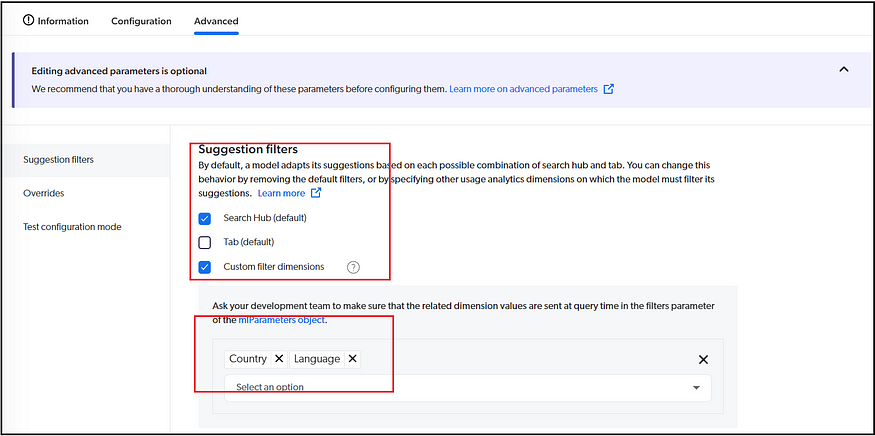
Also, you can enable the required filters to restrict the data specific to a scenario, e.g., limiting data to a particular country and language on multi-language websites.
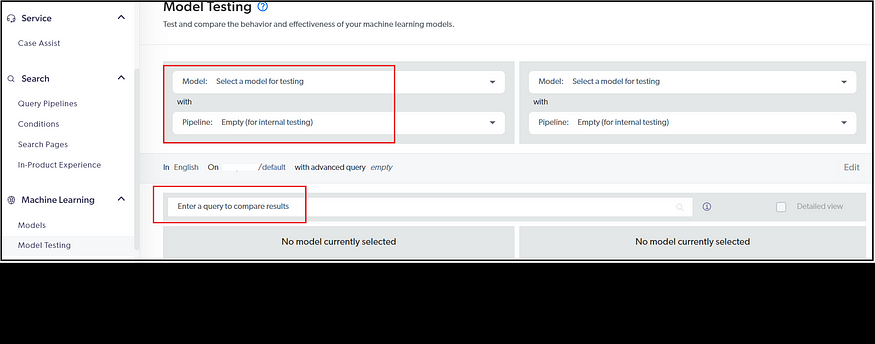
You can test the models through the model testing page.
Associate the Model to Query Pipeline
Sharing Data through API:
Sometimes, you may need to share the search data through an API in addition to the Search interfaces.
You can use GET or POST search API; sample GET URL
https://platform.cloud.coveo.com/rest/search/v2?organizationId=<<Organization ID>>&searchHub=<<xxx>>&access_token=<<Access Token>>&context={"country":"us","locale":"en"}&q= test
Specify the organization id, Search Hub also the necessary context data, e.g., country/language values.
Specify the query string to search the index, e.g., q=test
Enable a dedicated Access API key with minimal access to retrieve the search data
The response will have all the records matching the input query.
Access Management:
Multiple OOTB groups are available, e.g., Administrators, Analytics managers, Relevance Managers, etc.; the custom groups can be defined based on the use cases. Refer to Manage Groups (coveo.com) for more details on managing groups.
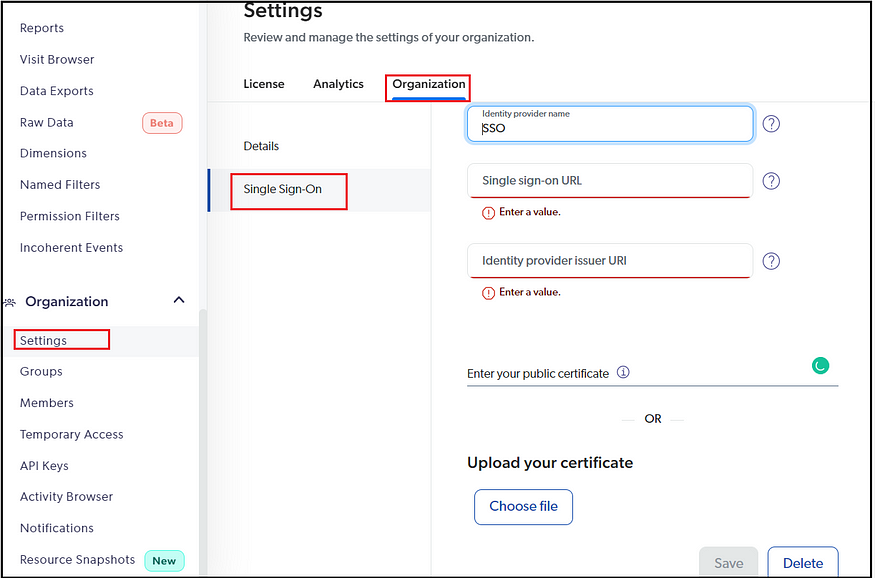
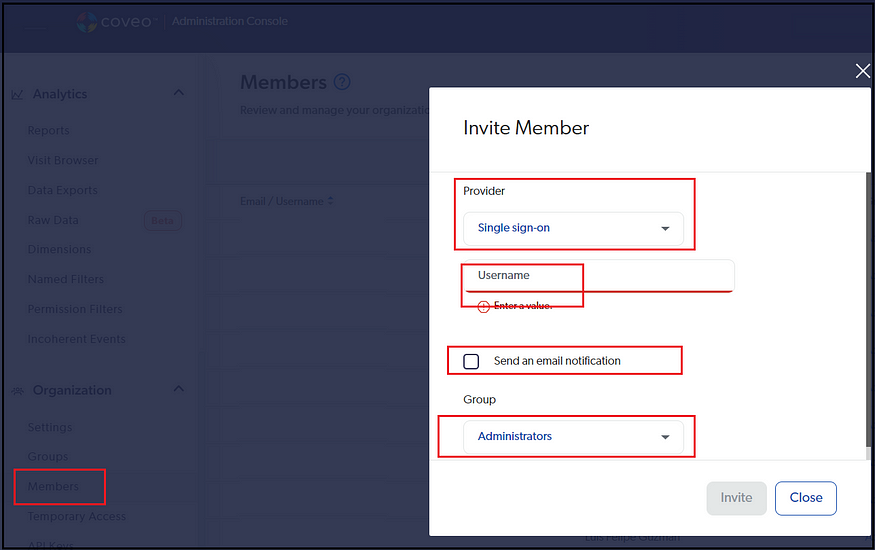
You can integrate your SSO(SAML) system to enable single sign-on behavior to the Coveo interfaces. Refer to Configure Coveo SAML SSO for more details on SSO configurations.
Select the Provider(different providers are available; Single sign-on if enabled; else other applicable providers. Enter the username; send the notification if required; select the Group.
Analytics:
Coveo analytics is designed to help you measure and optimize your Coveo solution. The Coveo-powered search interface captures and stores data in your Coveo organization. The data is then processed and made accessible through dashboards and explorers.
In addition to helping you measure your search solution adoption, usage analytics data also feeds Coveo Machine Learning (Coveo ML) algorithms to provide a more intuitive and personalized experience. Refer to Coveo Usage Analytics Overview for more details on Coveo analytics.
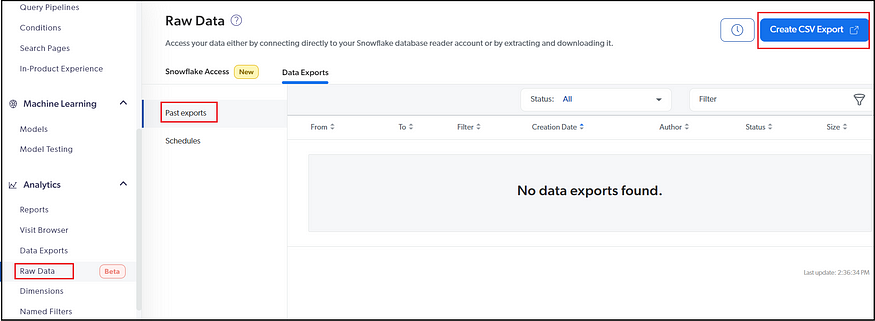
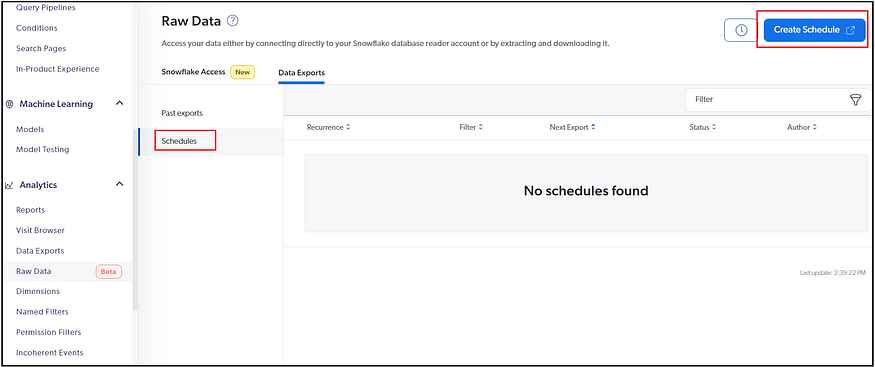
You can define the required dimensions and dashboards to review the usage data; the usage data can be exported as a CSV also scheduled at a specific interval.
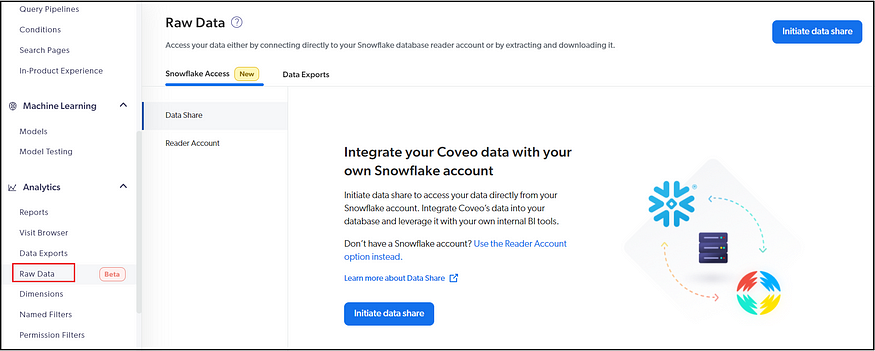
The data can also be shared with the organization’s snowflake account.
You can review the visitor details through the Visitor Browser.
Content Browser/Log browser:
The content browser page is a search interface that allows you to filter and inspect the content indexed in your Coveo organization. This page helps validate changes made to your organization and troubleshoot issues.
The Log Browser page of the Coveo Administration Console allows members with the required privileges to inspect the status of an item sent through the Coveo indexing pipeline.
Since each log corresponds to a stage of the indexing pipeline for a single item, you can retrieve precise information from this page after narrowing down your search. The Log Browser page is handy when troubleshooting indexing issues that apply to specific items. The custom messages can be logged from Python extensions — Logging Messages From an Indexing Pipeline Extension (coveo.com)
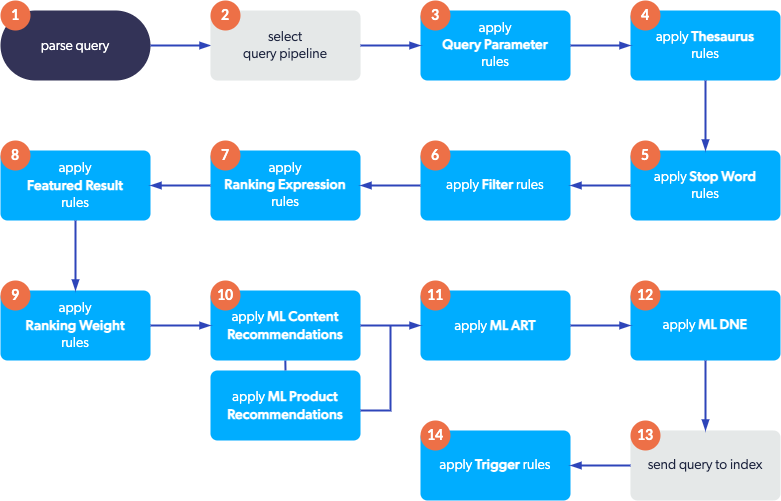
The following diagram shows the process of a query being sent to a given Coveo organization and the execution order of query pipeline features.
Whenever a query is made in your search hub, i.e., in one of your search interfaces, it passes through a query pipeline for optimization. The optimized query is then sent to the Coveo index, which returns matching items to display in the search interface.
The changes are initially enabled on the non-prod organization; the required configurations from the non-prod can be moved to the prod organization after successful post validation. You can use the Resource Snapshots to push the changes from the non-prod Organization to Prod Organization, or even the required changes can be manually applied to the prod organizations (mostly the source changes should be moved manually considering the source URL are different for no-prod and prod). Refer to Manage Resource Snapshots (coveo.com) for more details; you should be able to adjust Prod-specific values while moving the changes and only the selected resources.