AEM Core components deep dive | How to extend AEM core components | Proxy Components in AEM
This tutorial explains the details on AEM core components
In AEM, we use either custom or OOTB components to build the website, these components are called as WCM(Web Content Management) components.





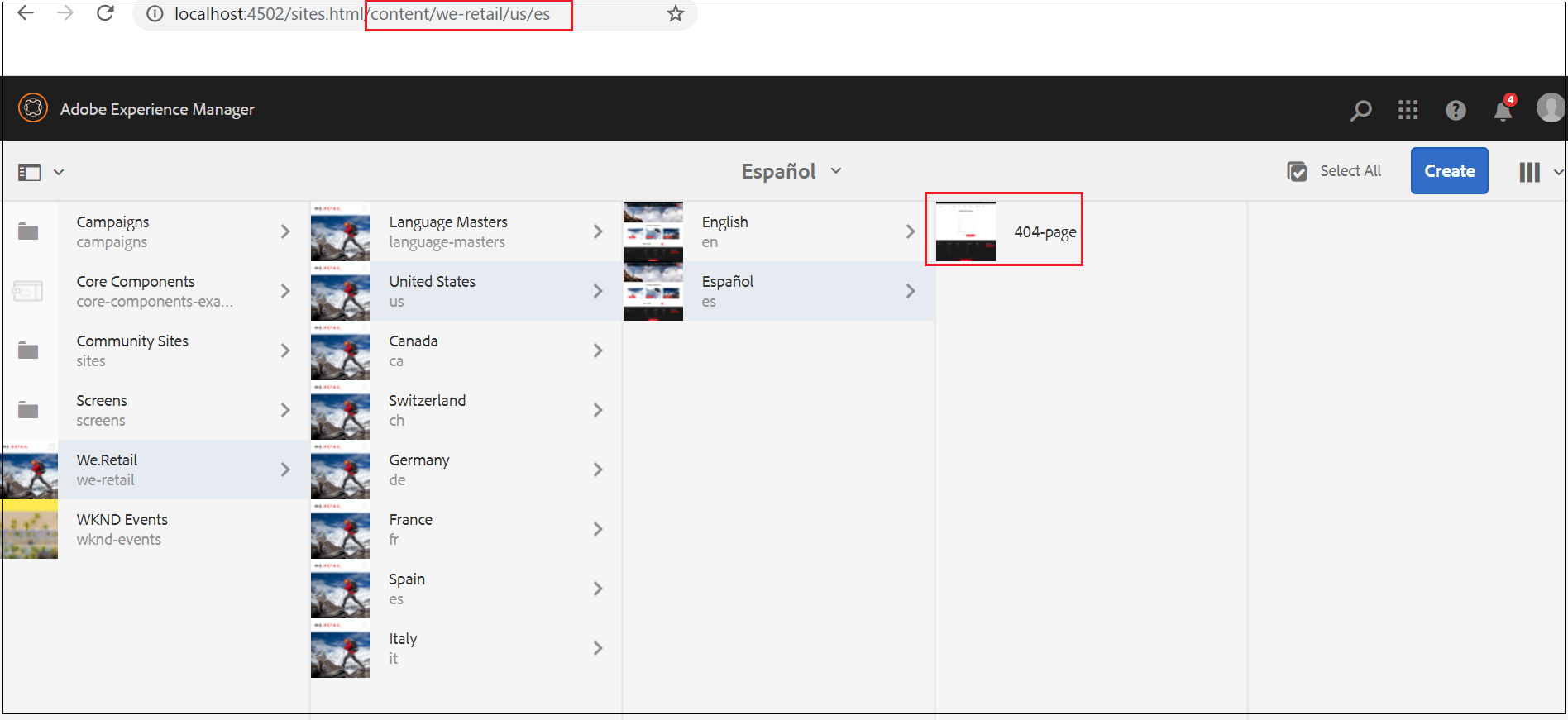
The Controller(Content) refers the proxy component (View), the proxy component is extended from WCM core components. Proxy Components are site-specific components which are inherited from core components, these are called as proxy component as no implementation is required but refers the core component as the resourceSuperType, can be extended as required.
The core components refers the Sling Model (Model) to retrieve the required data for rendering.
In AEM, we use either custom or OOTB components to build the website, these components are called as WCM(Web Content Management) components.

Core components
- introduced in AEM 6.2 but are strongly recommended to use from 6.3
- provides robust extensible base components
- built on the latest technology and follows the best practices
- adhering to accessibility guidelines and compliant with the WCAG 2.0 AA standard
- makes page authoring more flexible and customizable
- simple to extend to offer custom functionalities
Core components - Features

Core Components - Architecture

- Design dialog defines what authors can or cannot do it in the edit dialog
- Edit dialog shows authors only options they are allowed to use
- Sling model verifies and prepares the content for the view(template)
- The result of the sling model can be serialized to JSON for SPA use cases
- HTL renders the HTML server-side for traditional server-side rendering
- The HTML output is semantic, accessible, search-engine optimized and easy to style.
The Core components follows the MVC (Model View Controller) design pattern.


The Controller(Content) refers the proxy component (View), the proxy component is extended from WCM core components. Proxy Components are site-specific components which are inherited from core components, these are called as proxy component as no implementation is required but refers the core component as the resourceSuperType, can be extended as required.
The core components refers the Sling Model (Model) to retrieve the required data for rendering.
The Controller(Content) also refers the templates and configuration policies.
The Delegate pattern can be used to extend the model class for the core component, the responsibility of the model class is delegated to the implementations based on the resource type.
The core components uses the model interfaces and delegated to the right model implementation at runtime based on the resourceType in the model implementation.



Install the downloaded package through package manager, the core components are now enabled to the AEM instance

The Delegate pattern can be used to extend the model class for the core component, the responsibility of the model class is delegated to the implementations based on the resource type.
The core components uses the model interfaces and delegated to the right model implementation at runtime based on the resourceType in the model implementation.
Enable Core Components
The Core Components are open sourced through github, the components implementation and details can be referred from https://github.com/adobe/aem-core-wcm-components
Either one of the below approach can be followed to install the Core Components to AEM
- Install through package manager
- Include through code package
Install through package manager
The latest version is listed in the github page, the previous versions can be accessed by clicking on "Historical System Requirements"


Click on the version based on the system requirement and download the packages