How to use Attribute Loader in Adobe Search and Promote
This tutorial explains the details on how to use Attribute Loader in Adobe Search and Promote.
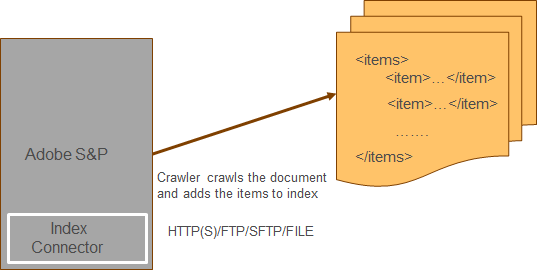
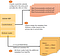
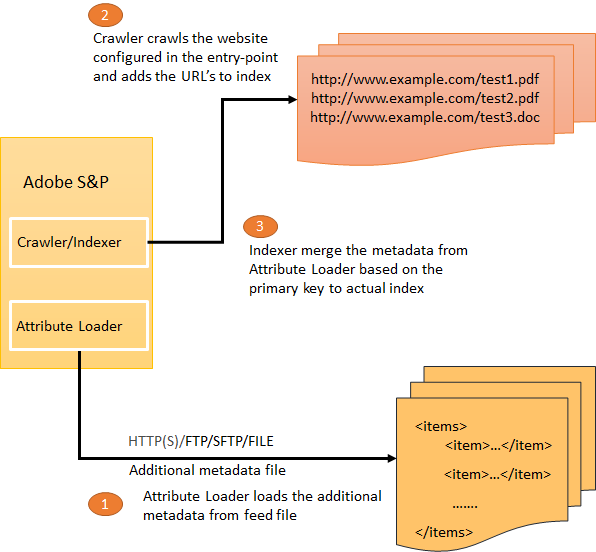
Attribute loader help us to provide additional meta data to the URL’s crawled from website.
For example, the PDF’s document crawled from the website will not have any additional metadata specified but the additional metadata can be loaded through Attribute Loader.
e.g while crawling the pdf document from website it will be possible to provide only pdf URL and file name but will not be able to provide the additional details like title, description etc, these additional metadatas can be provided via Attribute Loader.
The values will be merged during indexing through primary key value.
PDF URL Crawled from website — https://www.example.com/test/Albin.pdf
Additional Meta Data-
url- https://www.example.com/test/Albin.pdf(primary key)
Tittle — test PDF
Description — test PDF
The Attribute Loader is executed before actual indexing and the metadata data values are merged based on the primary key during indexing.
Defining Attribute Loader
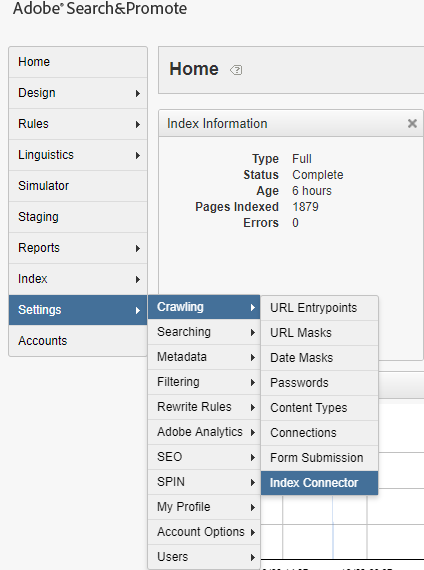
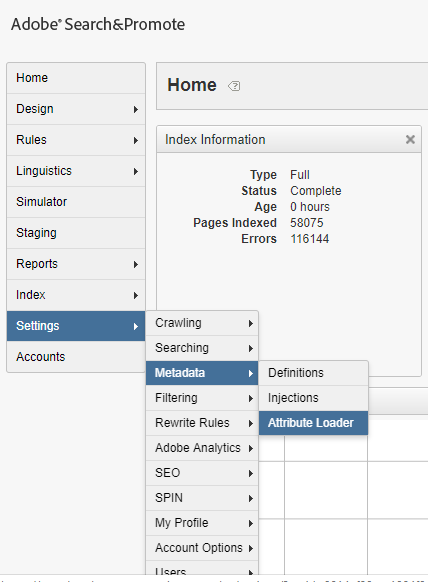
Attribute Loader option is available under Settings → Metadata →Attribute Loader
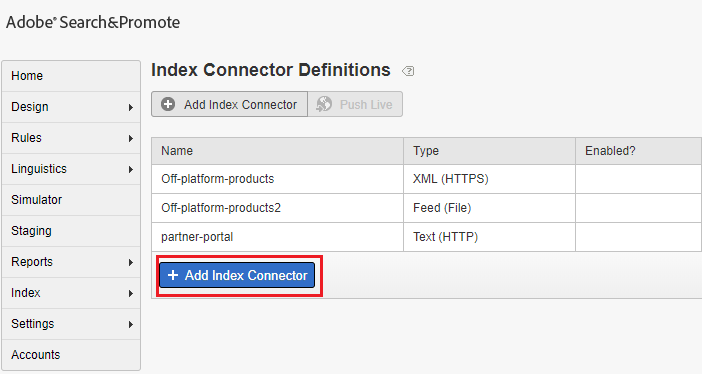
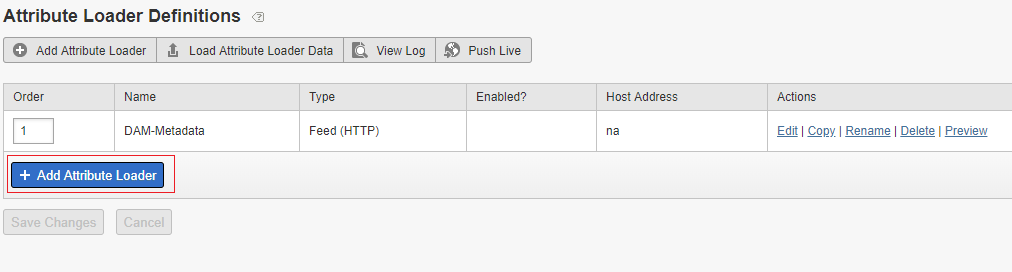
Add new Attribute Loader definition

Sample Feed XML with additional meta data , the data should be available through any one of the following channel — HTTP(S),FTP, sFTP and File
The meta data for each PDF document is represented by Item tag in the XML data
<attributes xmlns:xs=”http://www.w3.org/2001/XMLSchema" version=”2.0">
<channel>
<title>Attribute Loader Feed</title>
<Item>
<title>test PDF1</title>
<desc>test PDF1</desc>
<url>https://www.example.com/test/Albin1.pdf</url>
</Item>
<Item>
<title>test PDF2</title>
<desc>test PDF2</desc>
<url>https://www.example.com/test/Albin2.pdf</url>
</Item>
</channel>
</attributes>
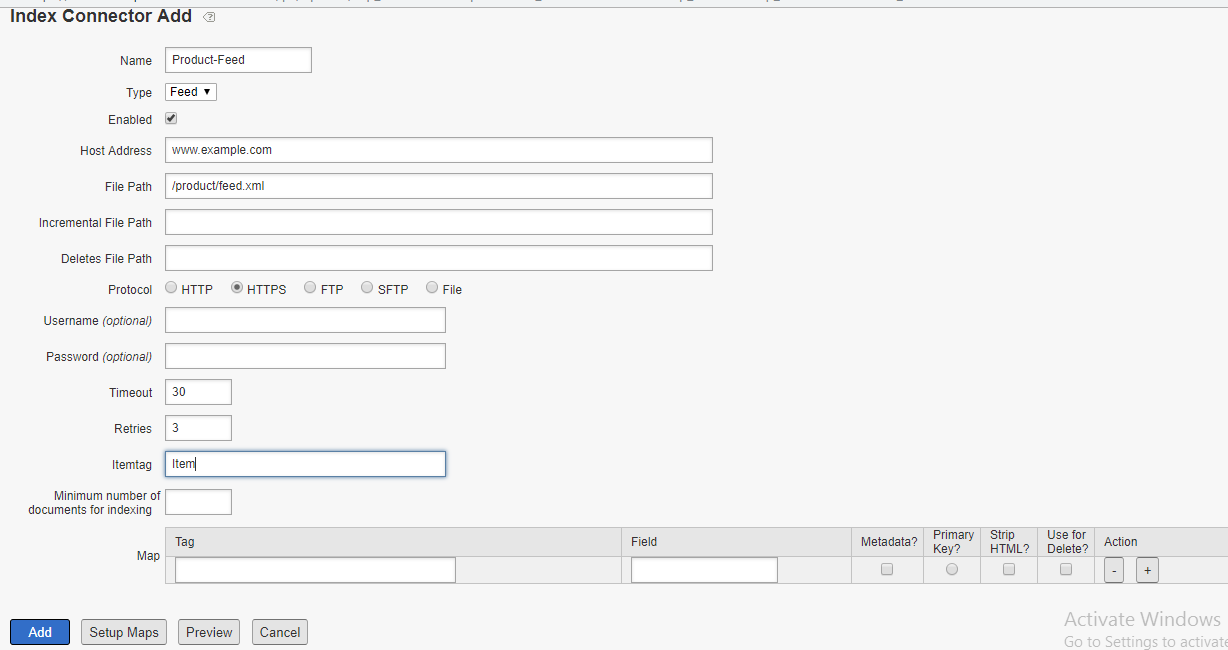
Enter the Feed details to the Attribute Loader
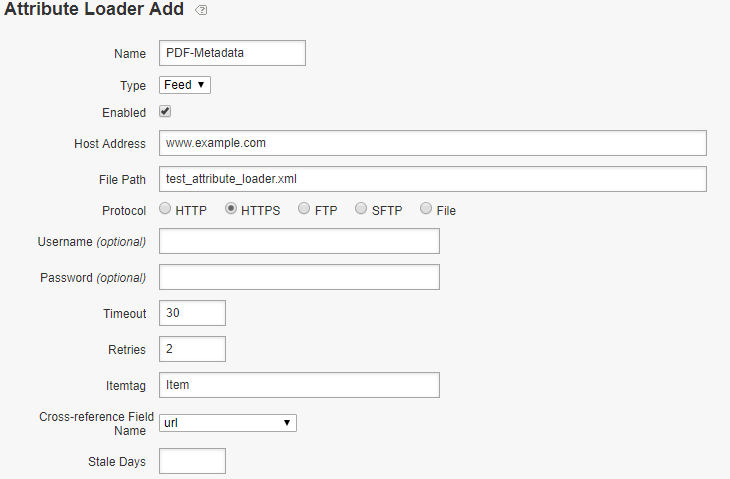
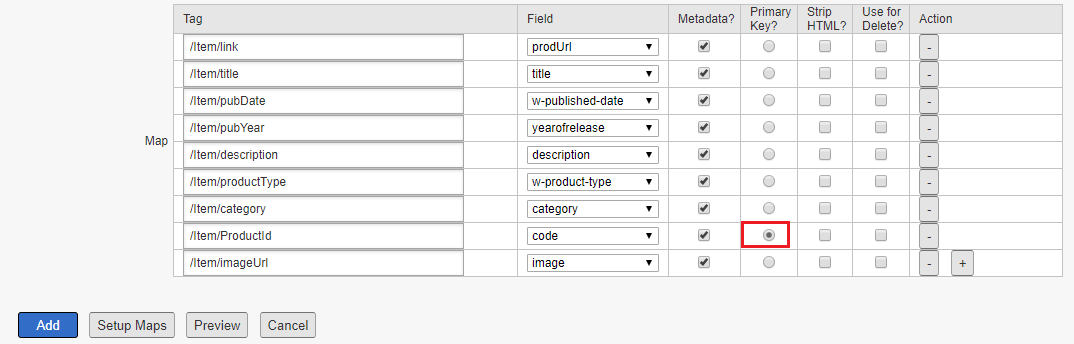
Map the Feed data fields to the Adobe S&P meta data definitions, specify a primary key to map the attribute loader data with the data crawled from other channels e.g website. Here the PDF URL is considered as a primary key, the URL is available through both website and Attribute Loader feed.
The Attribute Loader data is merged to the document based on the primary key during the indexing.

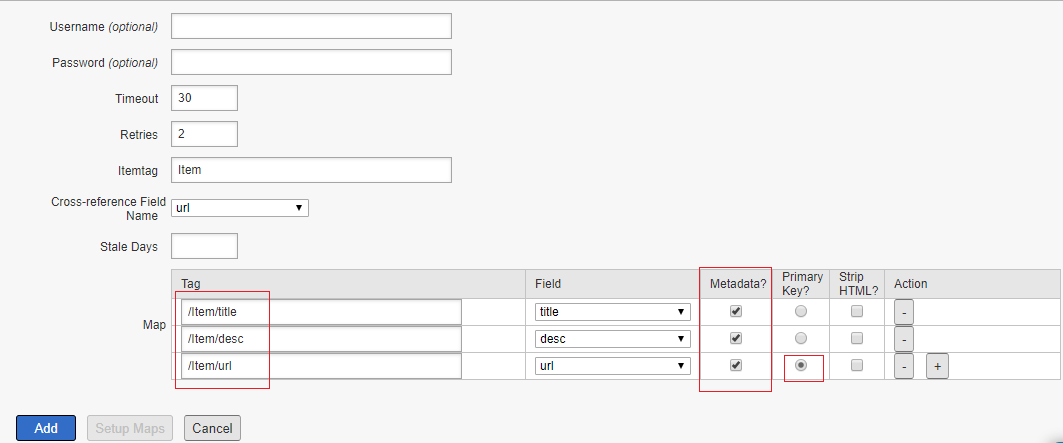
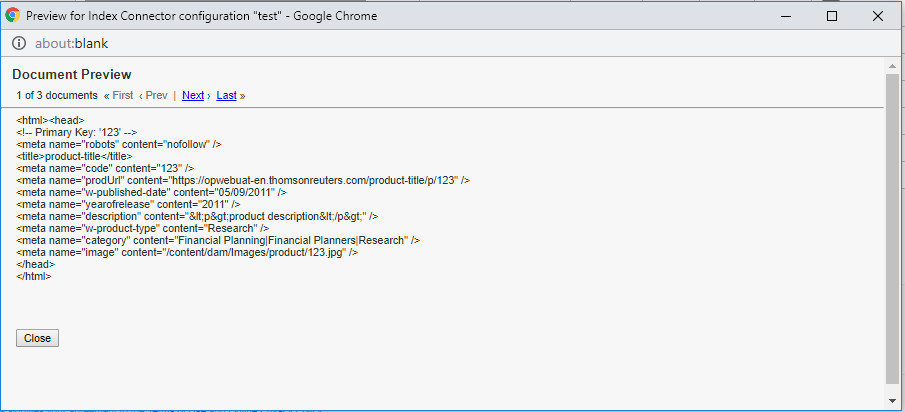
The Attribute Loader data can be previewed after configuration, to preview the Attribute Loader Data — Click on Load Attribute Loader Data then Start Load

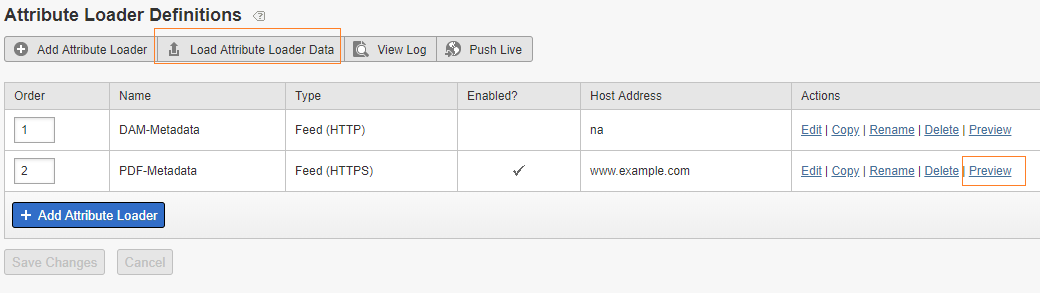
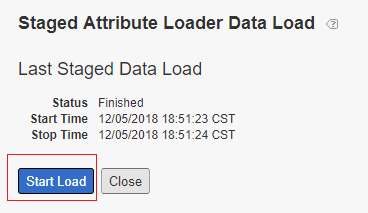
Click on Start Load, this will show the preview of the data loaded from the feed

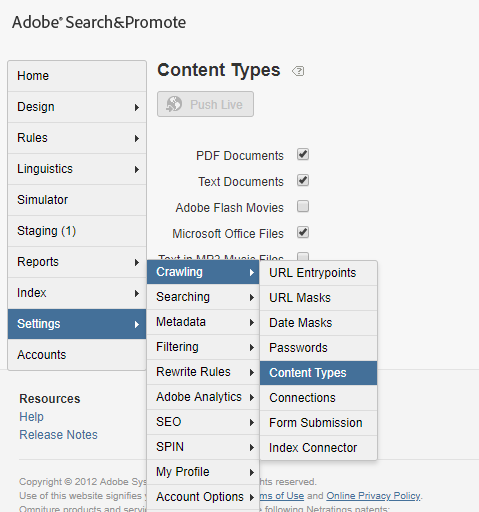
Make sure the Content-Types for the required document types(e.g application/pdf) are selected to enable the crawler to crawl those document types from website — the documents for those the Content Types enabled will be crawled from the website
The Content Types can be enabled from Settings → Crawling →Content Types
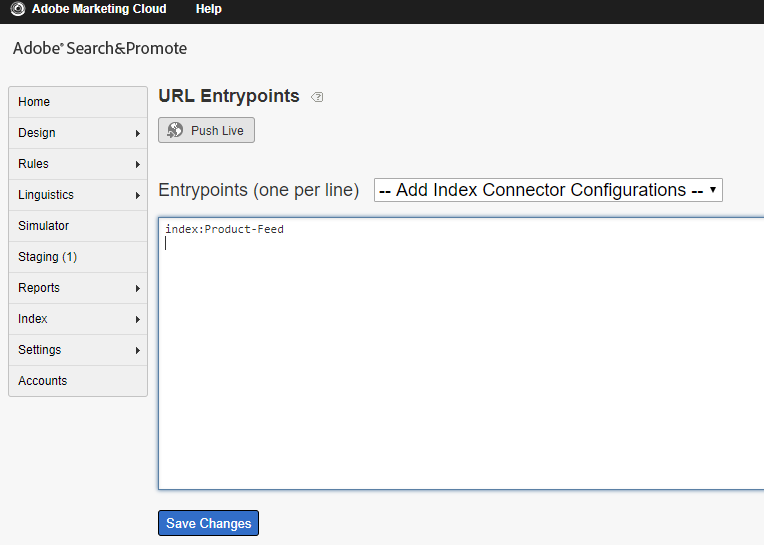
Configure the URL entrypoint — website URL from where the documents should be crawled and the URL mask — the matching URL that should be considered for crawling.
Settings →Crawling →URL Entrypoints
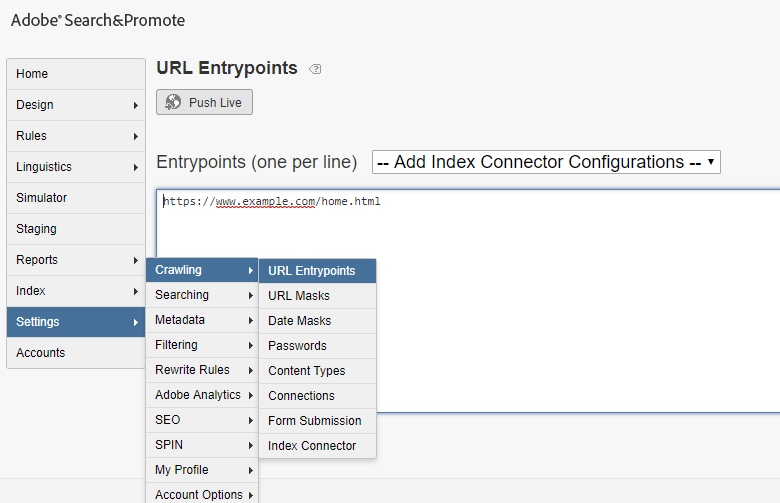
The URL mask can be enabled from Settings →Crawling →URL Masks
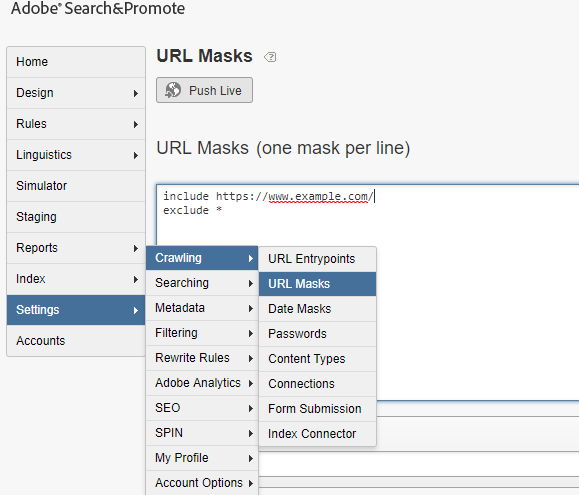
Sample URL
https://www.example.com/home.html
<html>
<body>
<a href=”https://www.example.com/test/Albin1.pdf">test1 pdf
<a href=”https://www.example.com/test/Albin2.pdf">test2 pdf
</body>
</html>
Run the live index by configuring the website URL entrypoint that has the reference to PDF documents, now the search result displays the metadata provided by Attribute Loader for PDF documents
The Attribute Loader is not enabled by default, this should be enabled in S&P account by your Adobe account representative or by Adobe Support.
The attribute loaders add the capability to provide additional meta data to the documents crawled through a channel that is enabled with limited data.