How to use Index Connector in Adobe Search and Promote
This tutorial explains the details on how to use Index Connector in Adobe Search and Promote.
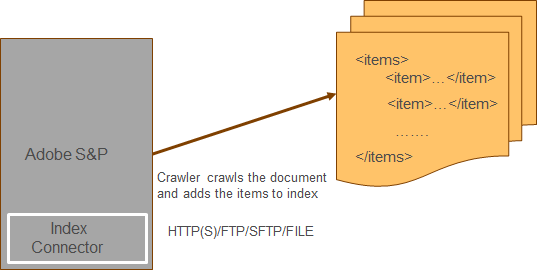
Index Connector
Index Connector enable us to define additional input sources for indexing XML pages or any kind of feed.
Search and Promote allows us to add the website URL’s as an entry point to crawl the pages for indexing, the URL’s also can be crawled and indexed through Index Connector.(the URL entry points and Index Connectors can be defined together for crawling and indexing)
For example, the Index Connector can be used to index the large number of product data from eCommerce systems to reduce the crawling and indexing time. Index Connector approach provides better crawling/indexing performance.
A XML data feed consists of records corresponds to the individual documents that can be added to the index
A text data feed contains new-line-delimited records corresponds to the individual documents that can be added to the index
Mapping can be enabled to map the feed data to the metadata fields in the resulting index
Multiple protocols can be used to connect to the input feed sources from Index Connector — HTTP(S)/FTP/SFTP/FILE
The IndexConnector is not enabled by default in S&P account, the same should be enabled by Adobe S&P account team.
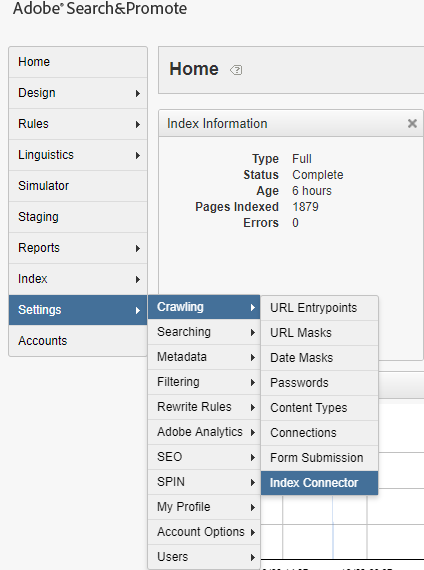
Define Index Connector
After enabling the Index Connector to the account, the same can be accessed from Settings →Crawling →Index Connector
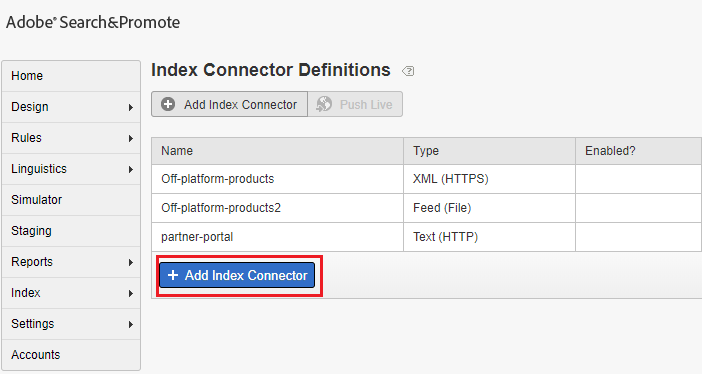
As a first step add a Index Connector
Sample product feed file(XML)
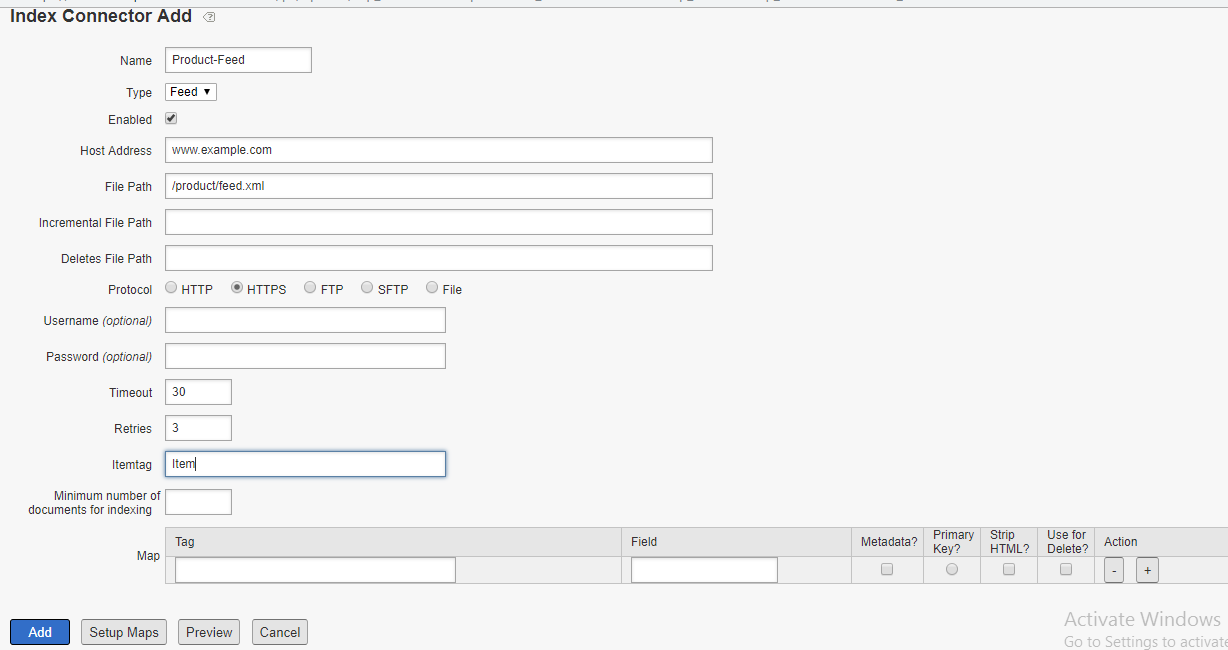
The feed file is available through HTTP(S) URL — www.example.com/product/feed.xml, the Index Connector can also access the feed through FTP, SFTP and FILE protocol’s.
Enter a name for the Index Connector
Select Type as Feed
Select Enabled
Configure Host Address and File Path
Select the appropriate Protocol
Configure the Timeout and Retries as required
Itemtag — tag represents the individual records
<feed xmlns:xs=”http://www.w3.org/2001/XMLSchema" version=”2.0">
<channel>
<title>Product Feed</title>
<Item>
<link>https://www.example.com/product-title/p/123</link>
<title>
<![CDATA[product-title]]>
</title>
<pubDate>05/09/2011</pubDate>
<pubYear>2011</pubYear>
<description>
<![CDATA[<p>product description</p>]]>
</description>
<productType>Research</productType>
<category>
<![CDATA[Financial Planning|Financial Planners|Research]]>
</category>
<ProductId>123</ProductId>
<imageUrl>/content/dam/Images/product/123.jpg</imageUrl>
</Item>
<Item>
<link>https://www.example.com/product-title/p/1234</link>
<title>
<![CDATA[product-title]]>
</title>
<pubDate>05/09/2011</pubDate>
<pubYear>2011</pubYear>
<description>
<![CDATA[<p>product description</p>]]>
</description>
<productType>Research</productType>
<category>
<![CDATA[Financial Planning|Financial Planners|Research]]>
</category>
<ProductId>1234</ProductId>
<imageUrl>/content/dam/Images/product/1234.jpg</imageUrl>
</Item>
<Item>
<link>https:/www.example.com/product-title/p/12345</link>
<title>
<![CDATA[product-title]]>
</title>
<pubDate>05/09/2011</pubDate>
<pubYear>2011</pubYear>
<description>
<![CDATA[<p>product description</p>]]>
</description>
<productType>Research</productType>
<category>
<![CDATA[Financial Planning|Financial Planners|Research]]>
</category>
<ProductId>12345</ProductId>
<imageUrl>/content/dam/Images/product/12345.jpg</imageUrl>
</Item>
</channel>
</feed>
The feed file is available through HTTP(S) URL — www.example.com/product/feed.xml, the Index Connector can also access the feed through FTP, SFTP and FILE protocol’s.
Enter a name for the Index Connector
Select Type as Feed
Select Enabled
Configure Host Address and File Path
Select the appropriate Protocol
Configure the Timeout and Retries as required
Itemtag — tag represents the individual records
Enable the mapping for the fields from feed file to metadata defined, define a primary key value that will identify each record uniquely.
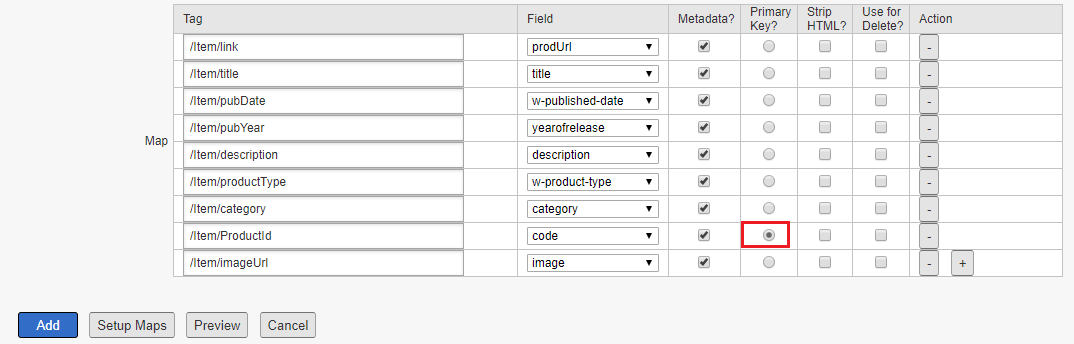
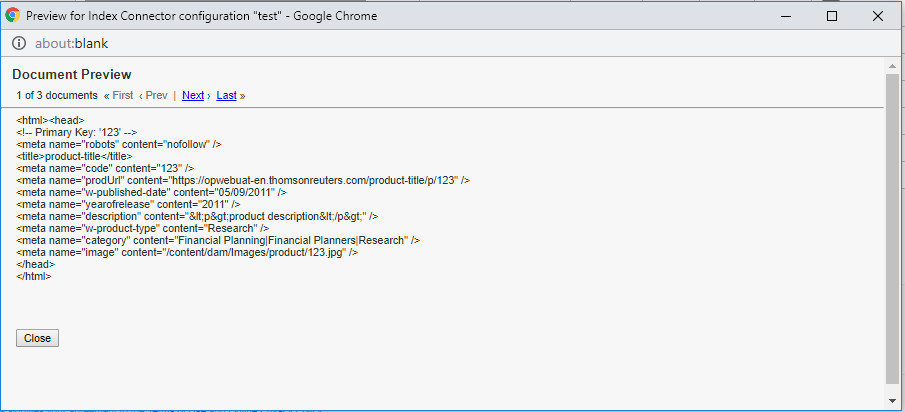
The configurations can be previewed before adding the Index Connector, click on Preview button
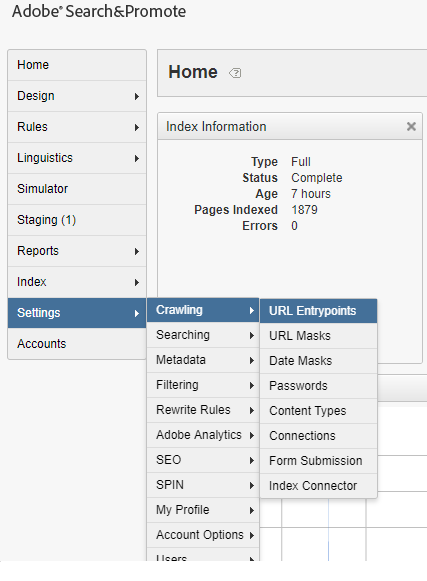
The Index Connector configuration is now ready, enable the Index Connector as URL entry point for crawling and indexing Setting → Crawling → URL Entrypoints
Select the Index Connector defined in the above step from the drop down “ — Add Index Connector Configurations — “
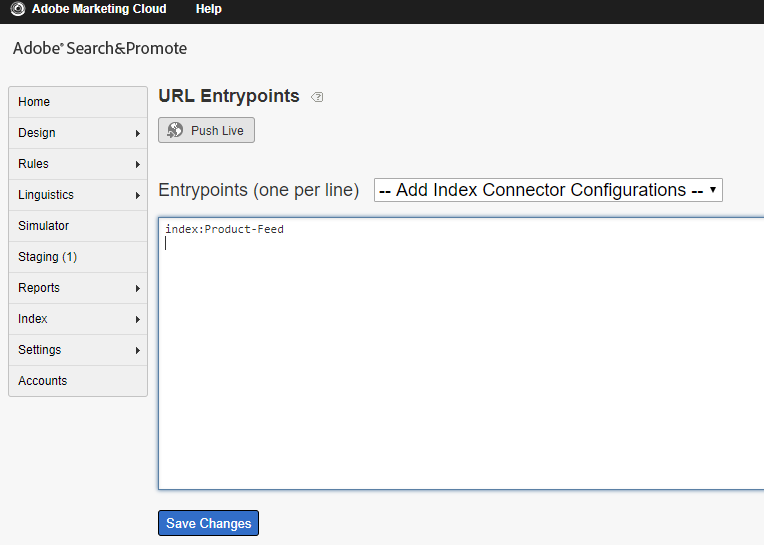
Now the configurations are ready, run a full live index so the new records will be reflected in the search result.
The Index Connector will provide the easy option to index the documents from feed data, this provides better performance during crawling and indexing. The Index connector can be used to index large volume of data for eCommerce systems.
No comments:
Post a Comment