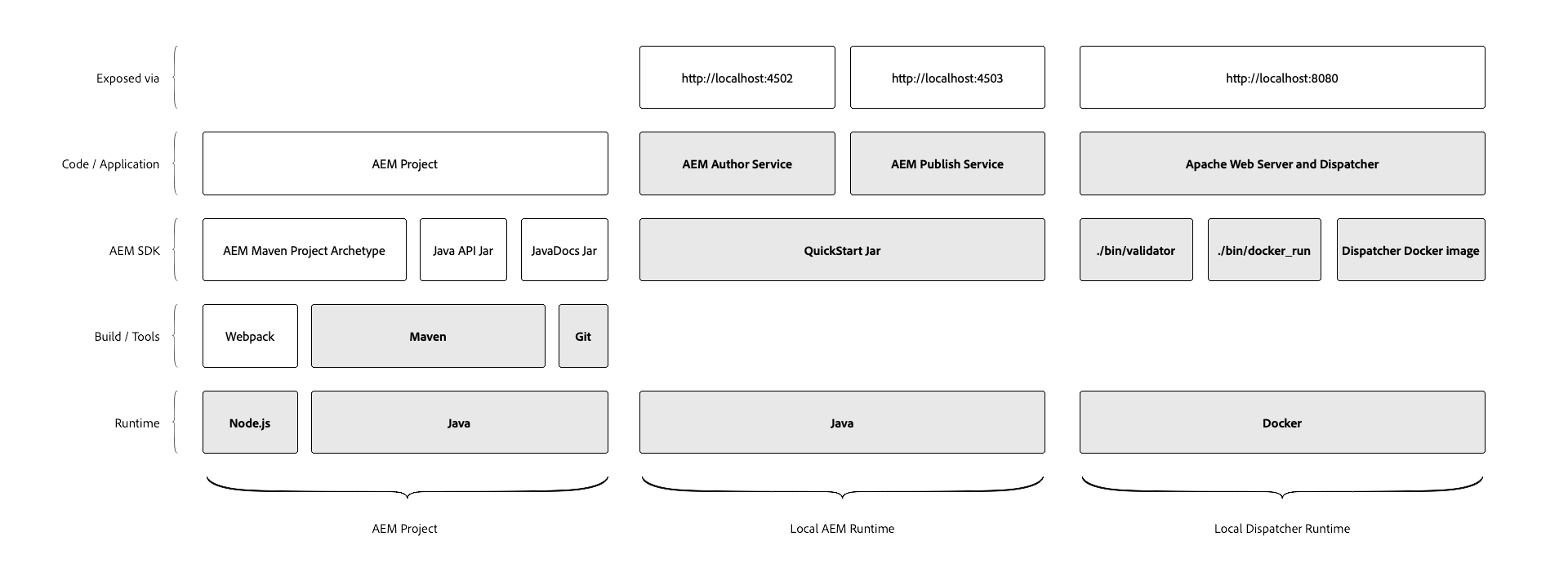
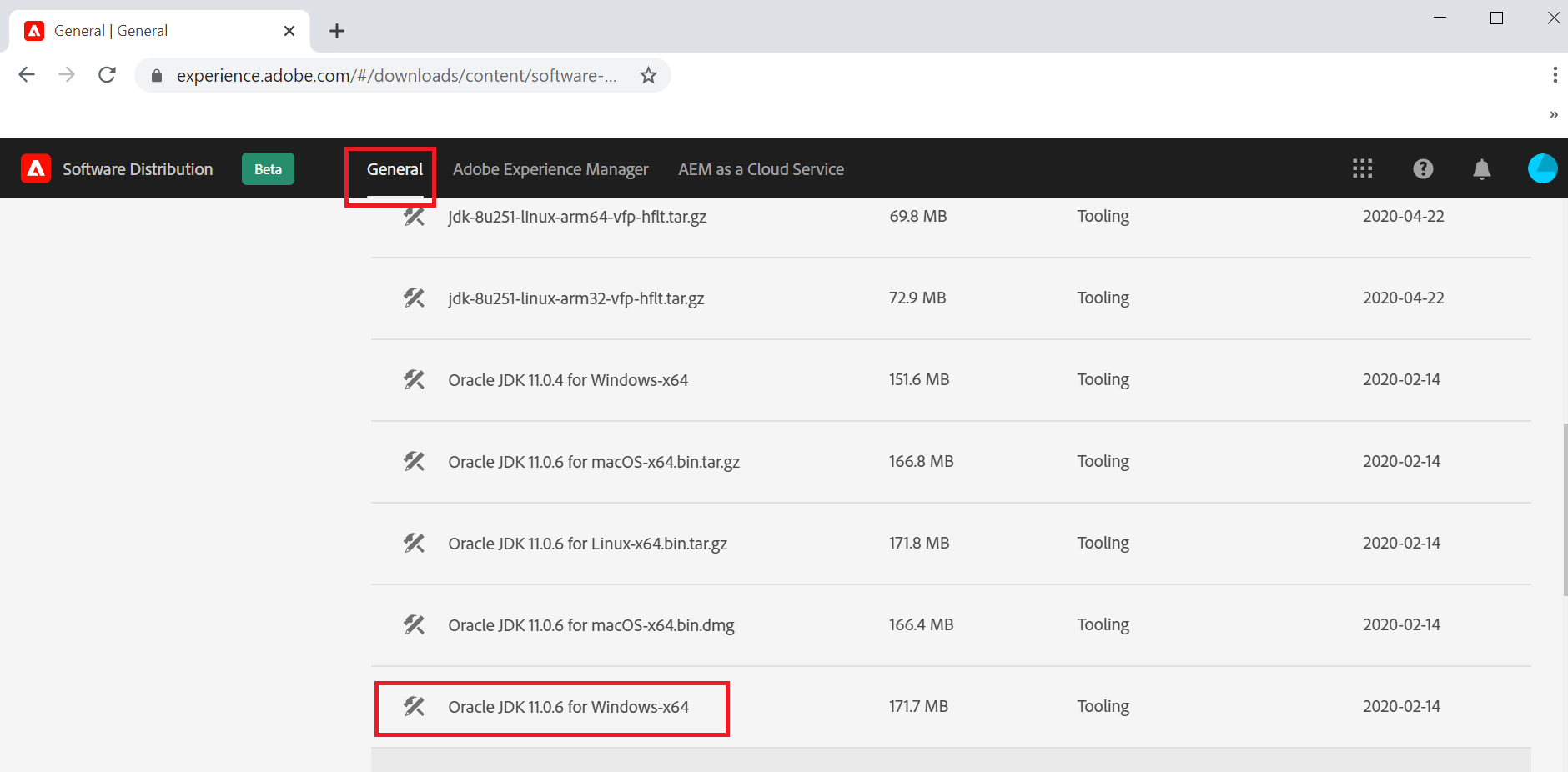
mvn -e -B archetype:generate -D archetypeGroupId=com.adobe.granite.archetypes -D archetypeArtifactId=aem-project-archetype -D archetypeVersion=23 -D aemVersion=cloud -D appTitle="My Site" -D appId="mysite" -D groupId="com.mysite" -D frontendModule=general -D includeExamples=n -DappsFolderName=mysi
Caused by: org.apache.maven.plugin.MojoFailureException: java.nio.file.FileSystemException: C:\Albin\blogData\demo\mysite\dispatcher\src\conf.d\enabled_vhosts\default.vhost: A required privilege is not held by the client.
at org.apache.maven.archetype.mojos.CreateProjectFromArchetypeMojo.execute (CreateProjectFromArchetypeMojo.java:207)
at org.apache.maven.plugin.DefaultBuildPluginManager.executeMojo (DefaultBuildPluginManager.java:137)
at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:210)
at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:156)
at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:148)
at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:117)
at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:81)
at org.apache.maven.lifecycle.internal.builder.singlethreaded.SingleThreadedBuilder.build (SingleThreadedBuilder.java:56)
at org.apache.maven.lifecycle.internal.LifecycleStarter.execute (LifecycleStarter.java:128)
at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:305)
at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:192)
at org.apache.maven.DefaultMaven.execute (DefaultMaven.java:105)
at org.apache.maven.cli.MavenCli.execute (MavenCli.java:957)
at org.apache.maven.cli.MavenCli.doMain (MavenCli.java:289)
at org.apache.maven.cli.MavenCli.main (MavenCli.java:193)
at sun.reflect.NativeMethodAccessorImpl.invoke0 (Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke (NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke (DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke (Method.java:498)
at org.codehaus.plexus.classworlds.launcher.Launcher.launchEnhanced (Launcher.java:282)
at org.codehaus.plexus.classworlds.launcher.Launcher.launch (Launcher.java:225)
at org.codehaus.plexus.classworlds.launcher.Launcher.mainWithExitCode (Launcher.java:406)
at org.codehaus.plexus.classworlds.launcher.Launcher.main (Launcher.java:347)
This is the know issue with Adobe Maven Arch Type 23 - refer https://github.com/adobe/aem-project-archetype for details.
The issue can be fixed by running the Maven command as a Elevated user or Run as Administrator.