This tutorial explains how to share or access the local files externally through ngrok and Python http server.
I have the below two scenarios
- a set of files that needs to be shared outside
- share a simple website externally
The above scenarios can be achieved through Apache Server and external DNS configurations but require more configurations efforts.
Prerequisites
- ngrok free or paid version
- Python latest version
Let us see how to enable the above scenarios through ngrok and python HTTP server with minimal configuration effort.
As a first step download ngrok(ngrok.com) for the required OS and extract the files
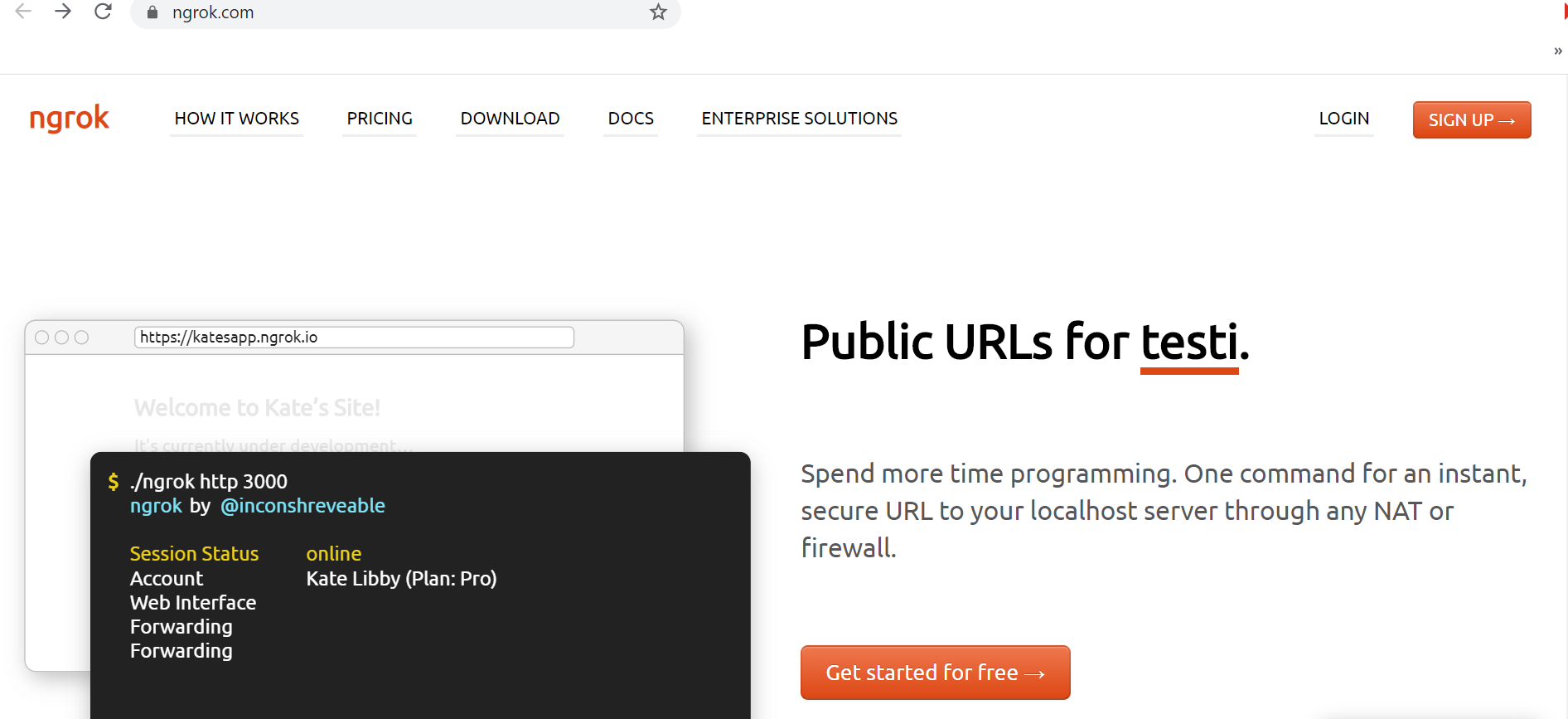
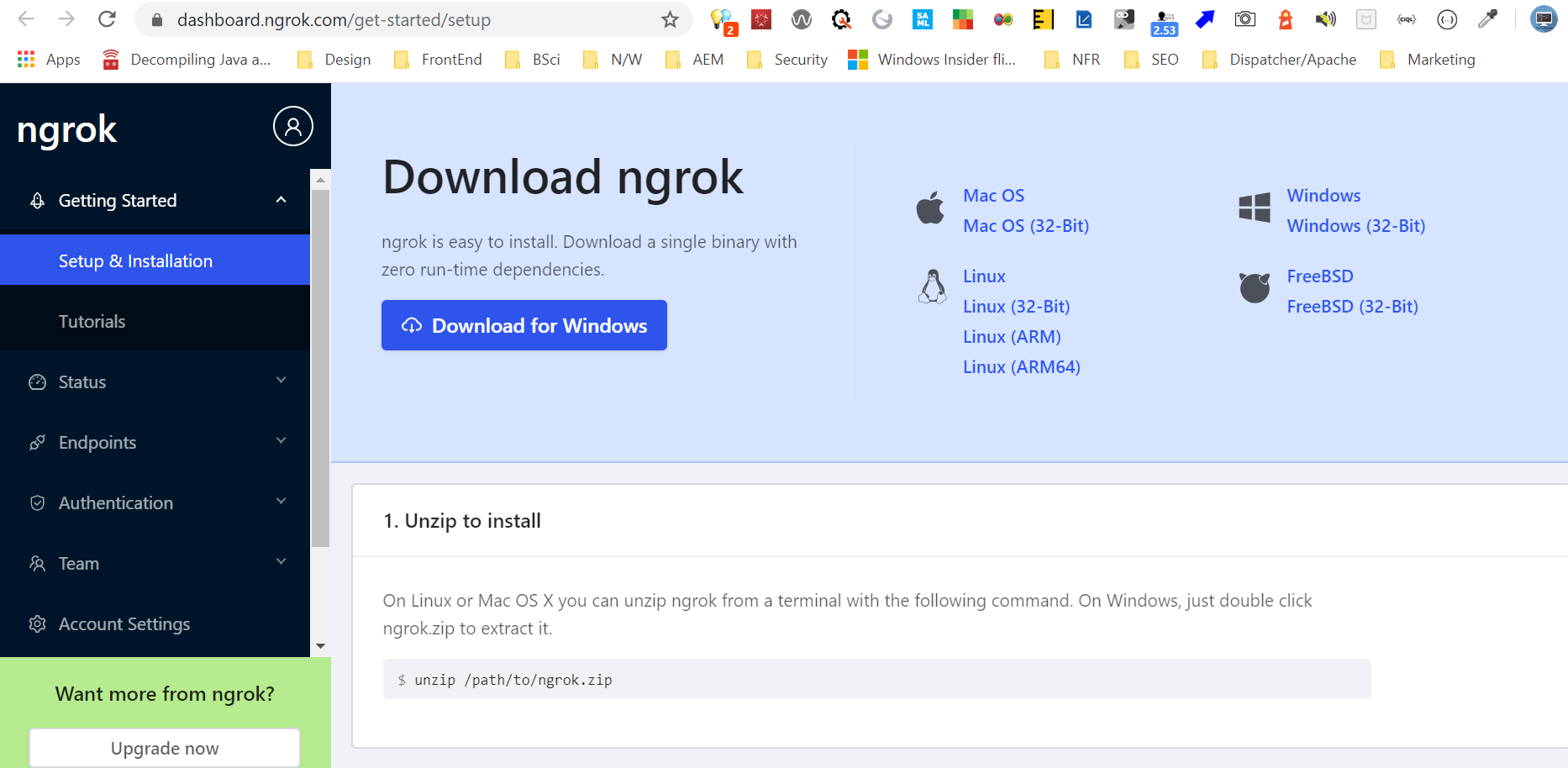
The ngrok allows you to expose a webserver running on your local machine to the internet. Just tell ngrok what port your web server is listening on.
On the free plan, ngrok’s URLs are randomly generated and temporary. If you want to use the same URL every time, you need to upgrade to a paid plan so that you can use the subdomain option for a stable URL. There are different paid plans they will provide some advance features like custom/reserved domains and multiple tunnels etc

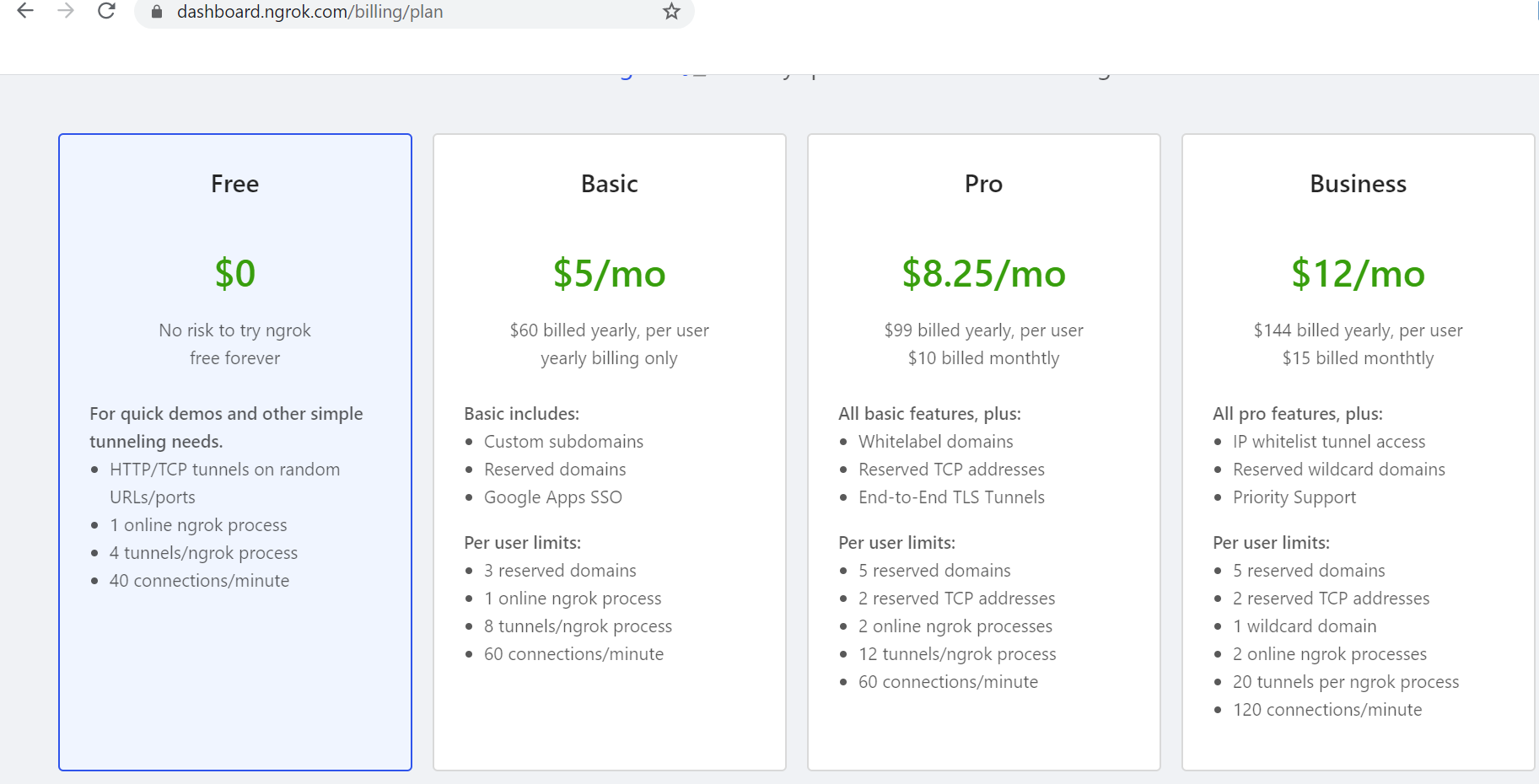
How ngrok works
You download and run a program on your machine and provide it the port of a network service, usually a web server.
It connects to the ngrok cloud service which accepts traffic on a public address and relays that traffic through to the ngrok process running on your machine and then on to the local address you specified.
Python HTTP Server
The required port number can be assigned and the web server is accessed through this port
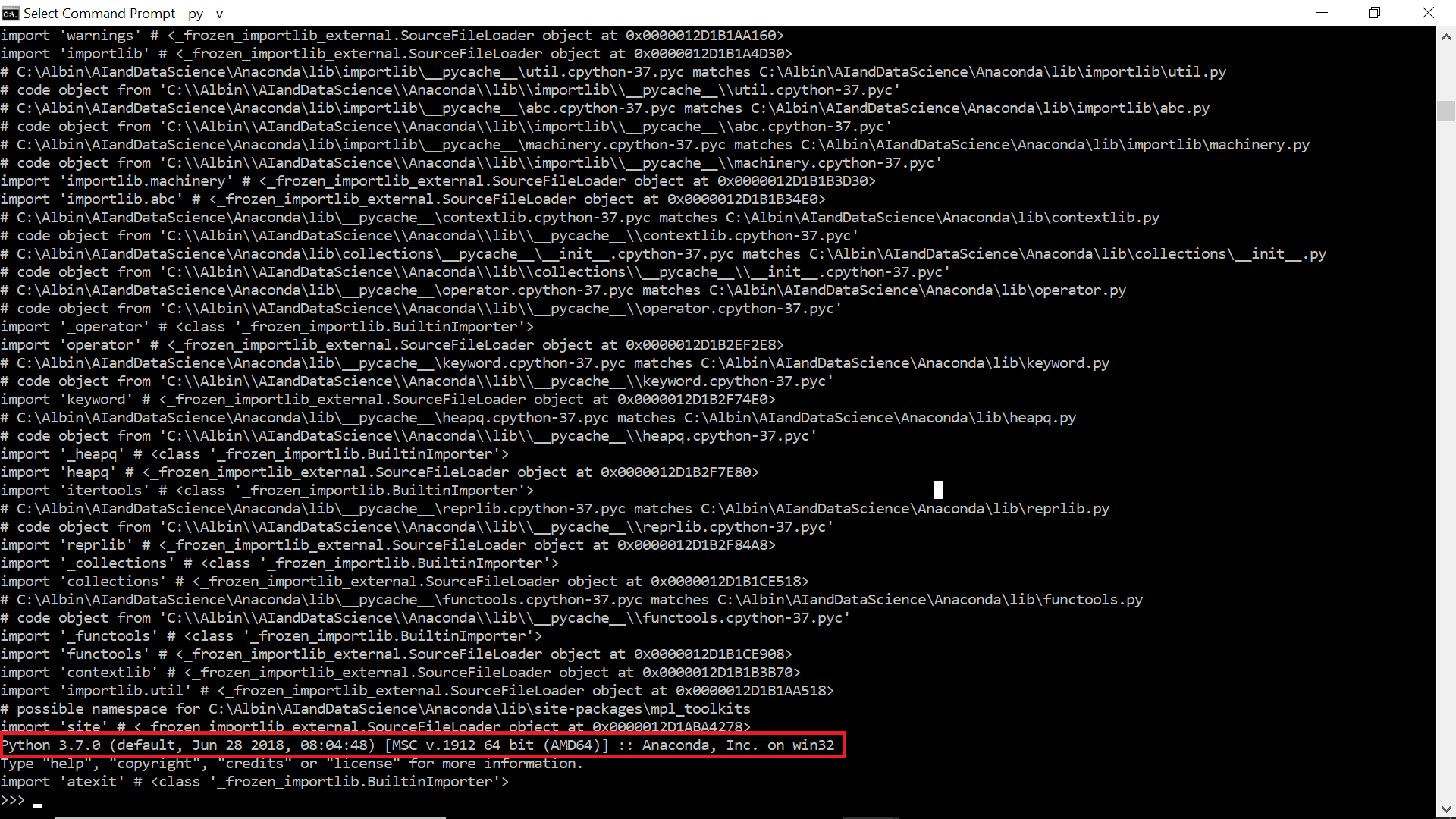
My system has python version 3.7.0 installed— “py -vi”
In the first scenario, i want to share some regular files externally
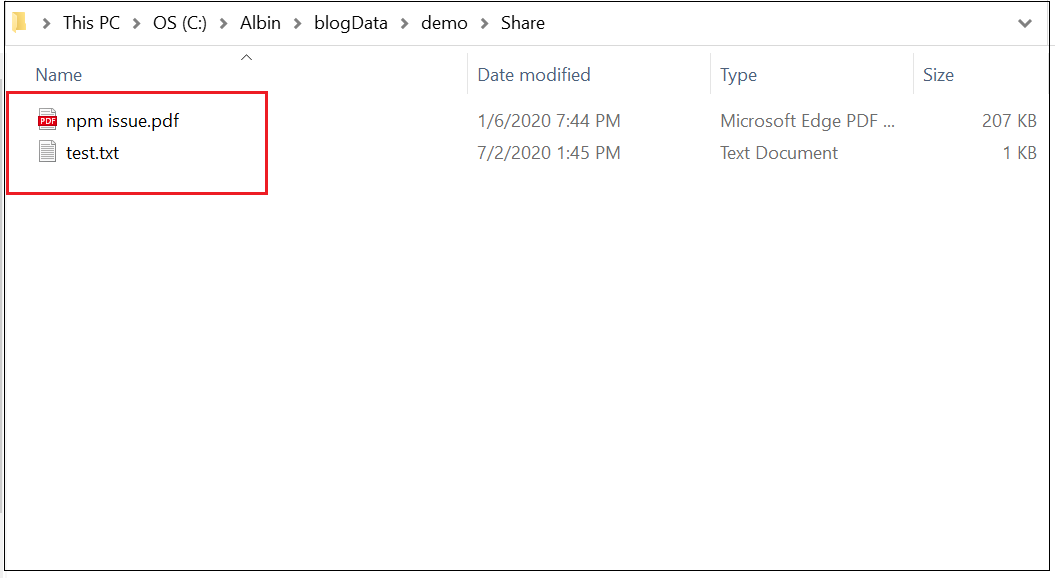
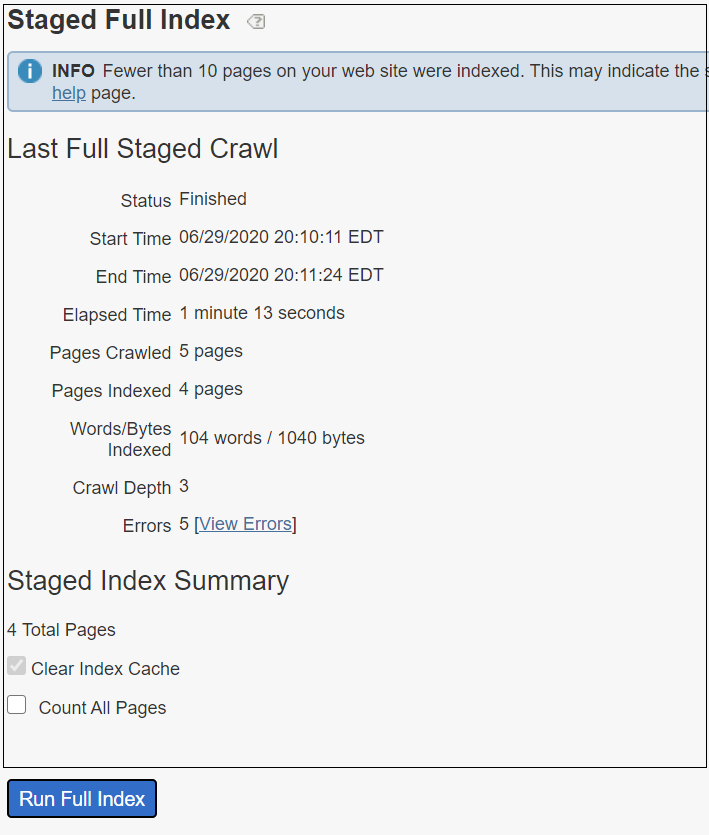
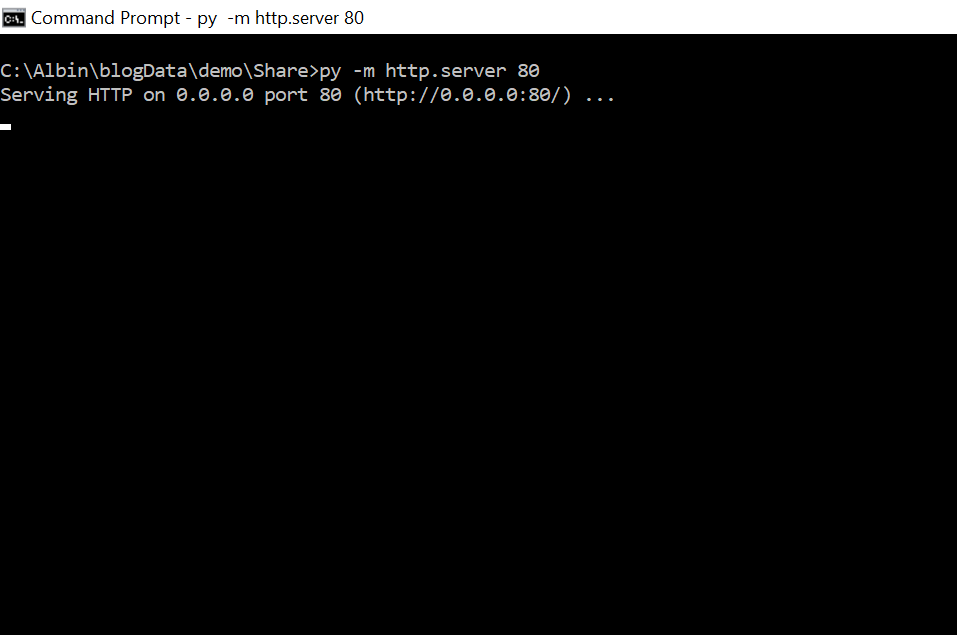
To start the HTTP server, cd to to the folder that should be shared(C:\Albin\blogData\demo\Share) through command prompt and execute the command “py -m http.server 80” — change the port number as required
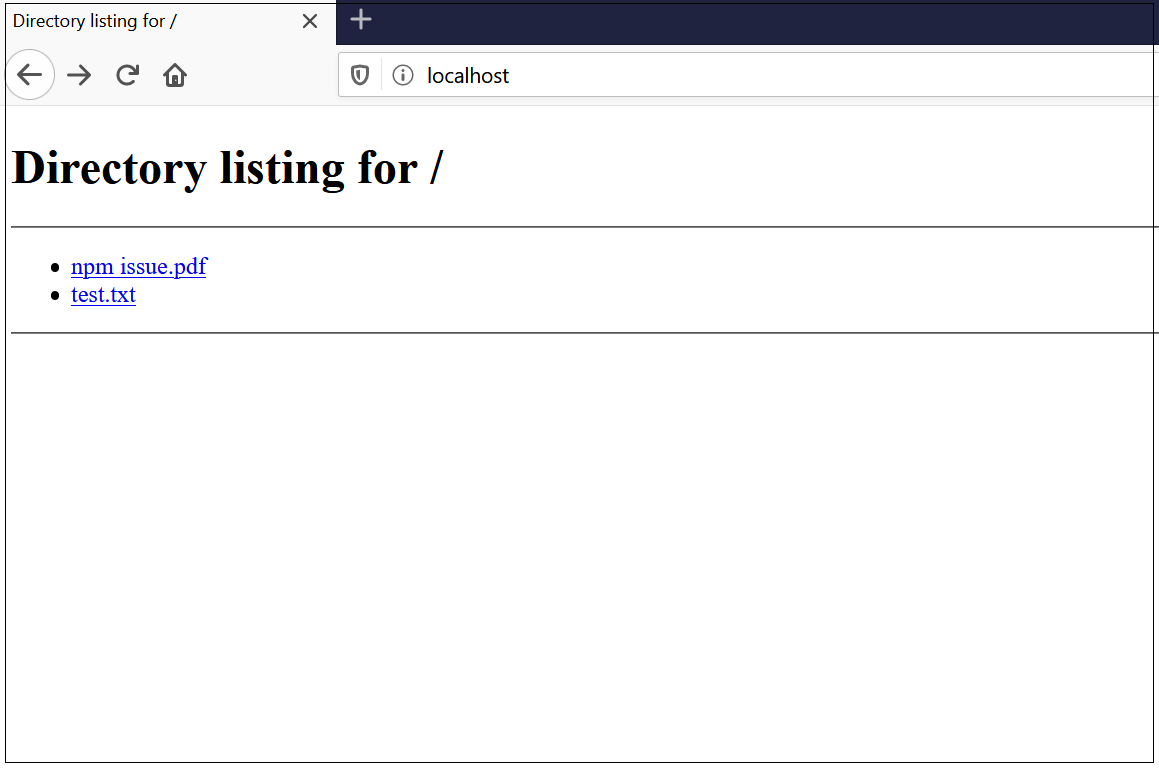
Now the files are accessible through localhost
Let's now start ngrok to share this folder externally, cd to the folder where ngrok was extracted(C:\Albin\SW\ngrok-stable-windows-amd64)
Execute “ngrok.exe http 80”(80 is where python HTTP server running)
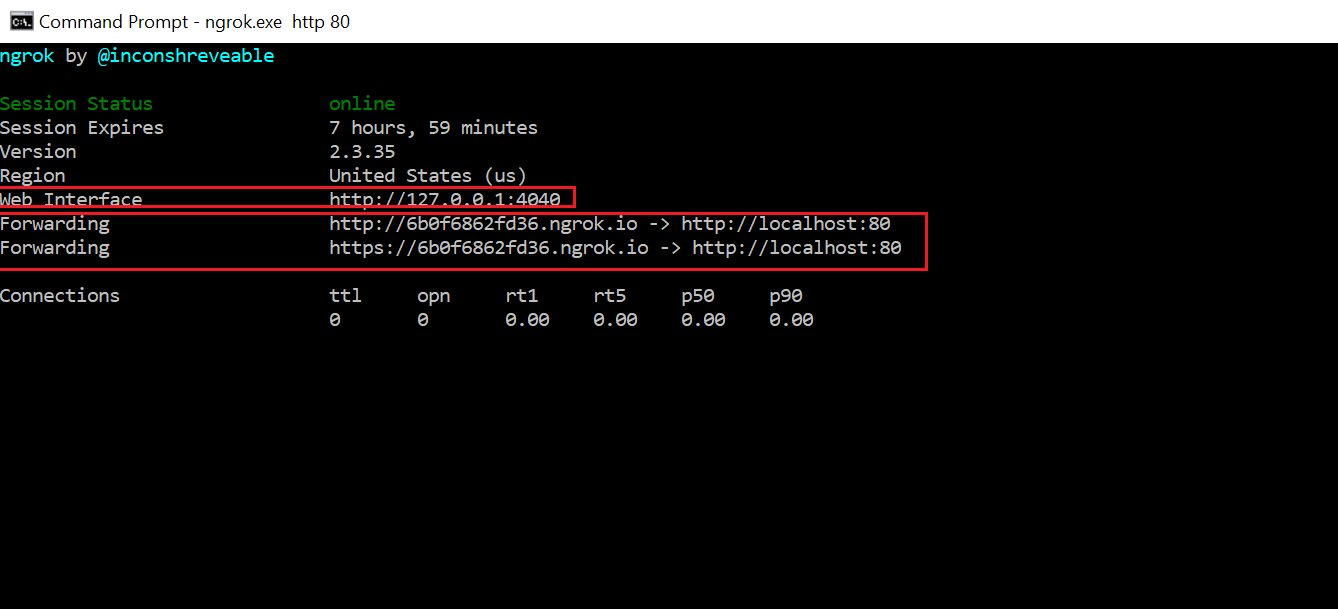
Now the external requests(http/https) are forwarded to localhost webserver through ngrok proxy domain
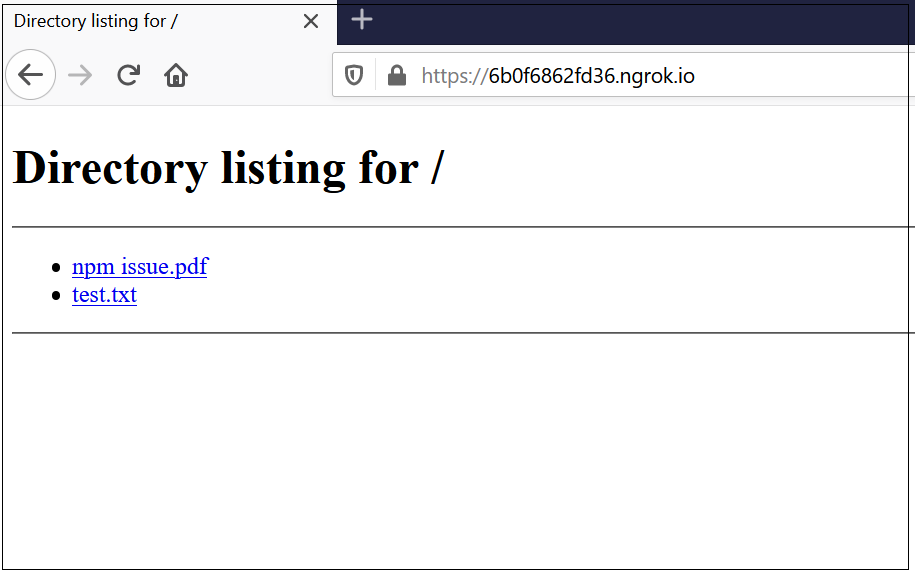
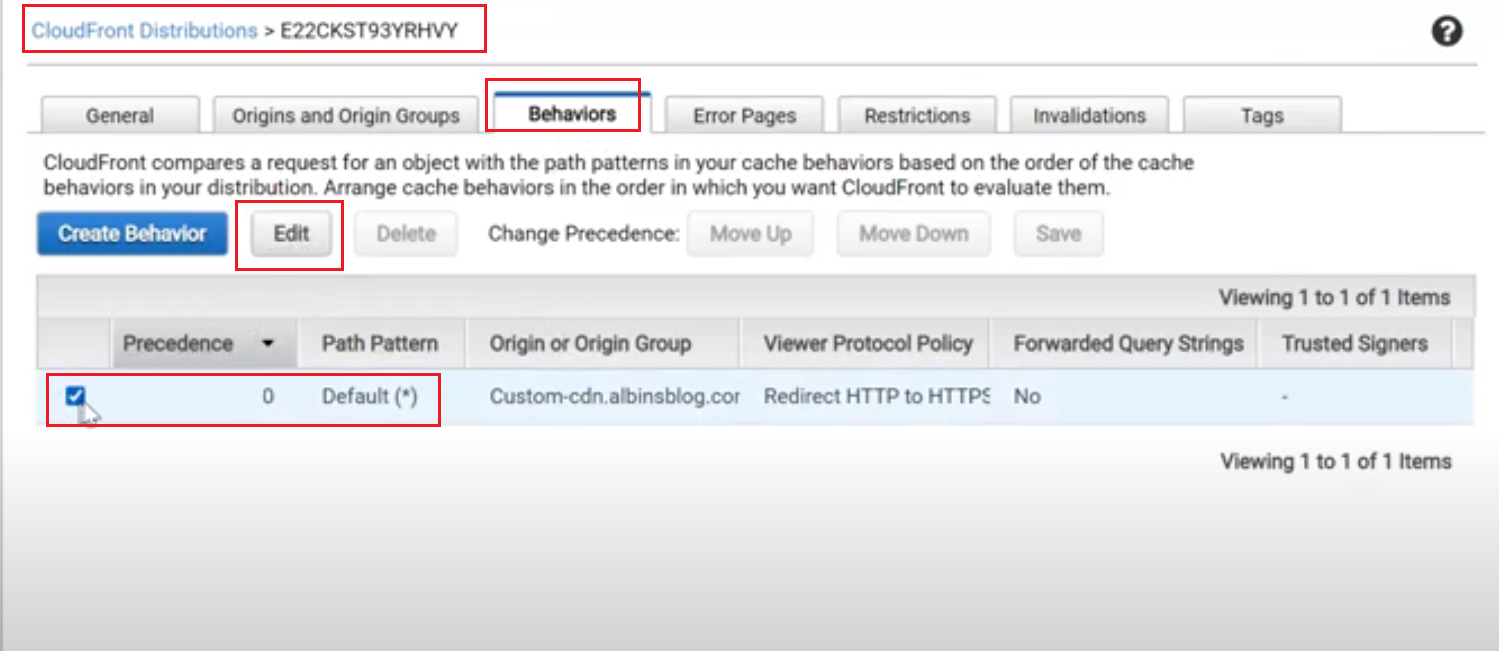
The local folders can be shared directly without a HTTP server through inbuilt ngrok file server. To share the local folder directly through ngrok , as a first step configure the authtoken to the ngrok
The authtoken can be retrieved through ngrok dashboard — the user should signup for a account , copy the command to set the authtoken by navigating to the dashboard.
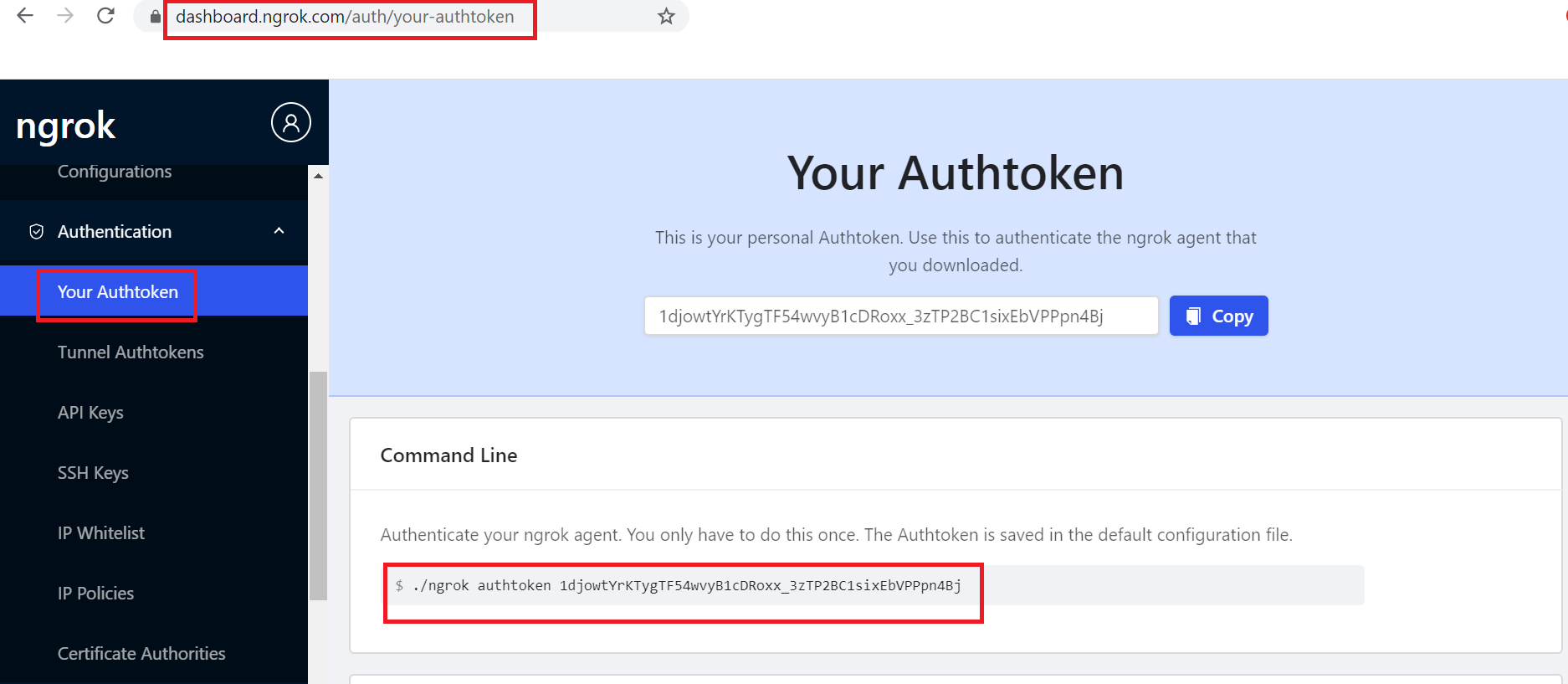
Execute the command

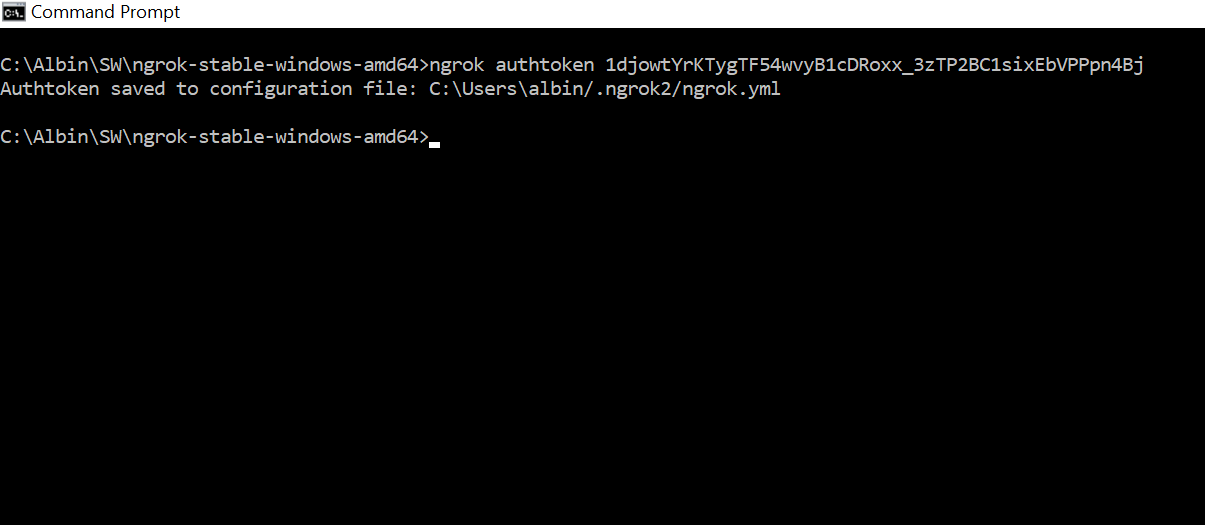
Start the ngrok process — e.g ngrok http “file:///C:\Albin\blogData\demo\blogproject.blogproject
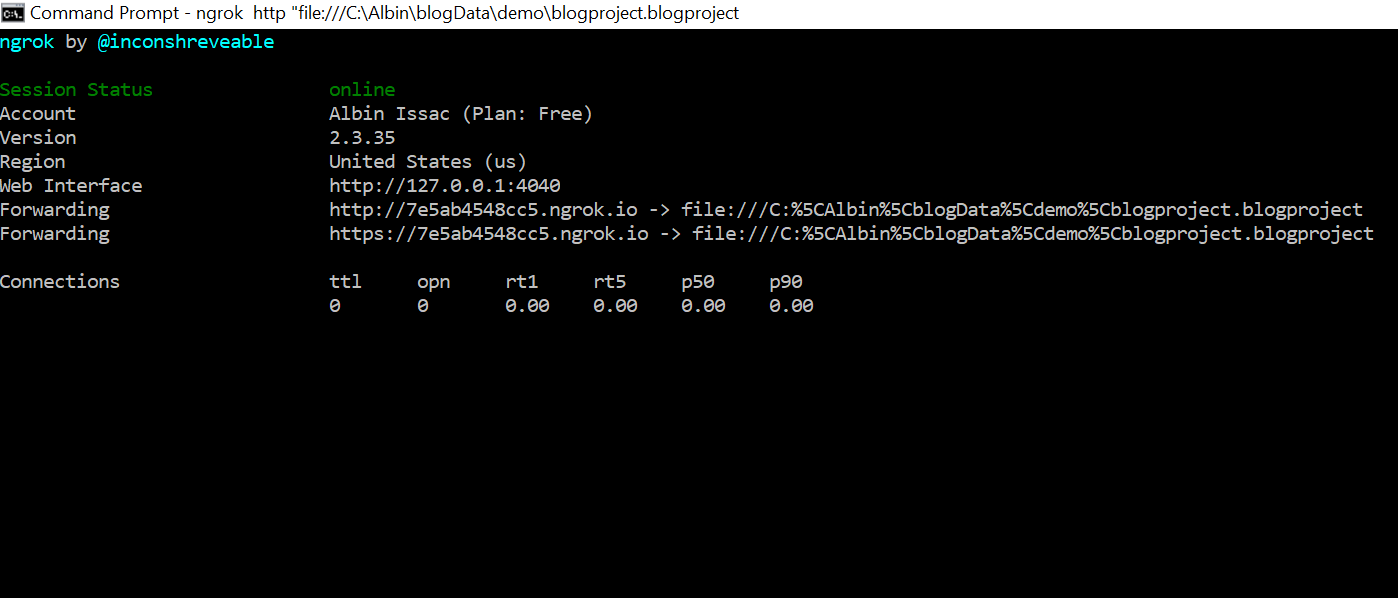
Now the files under the specific folder is accessible externally
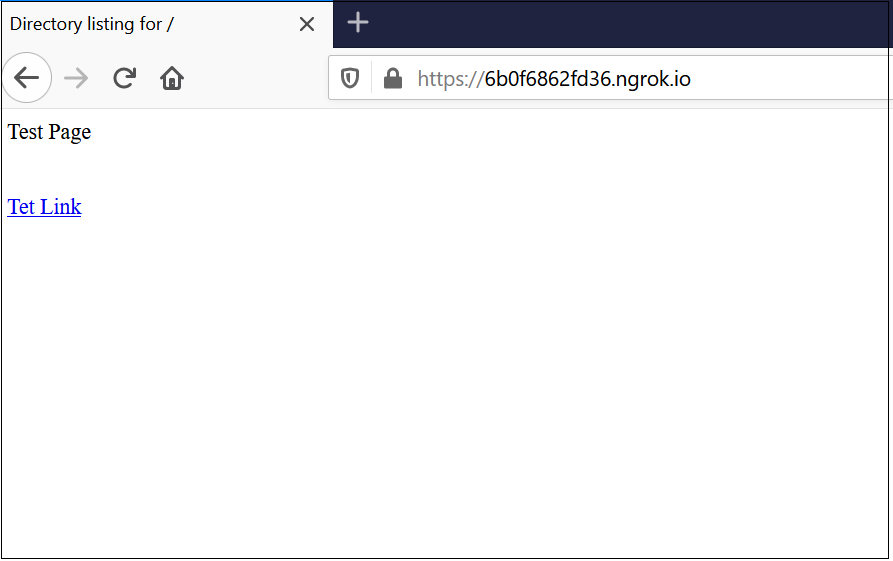
Let us now see how to enable the second scenario, to access simple website externally, created a index.html file along with some test files into a folder(C:\Albin\blogData\demo\site), cd to the folder where the index.html and other files are located
Re-start the HTTP server, the pages are now accessible outside
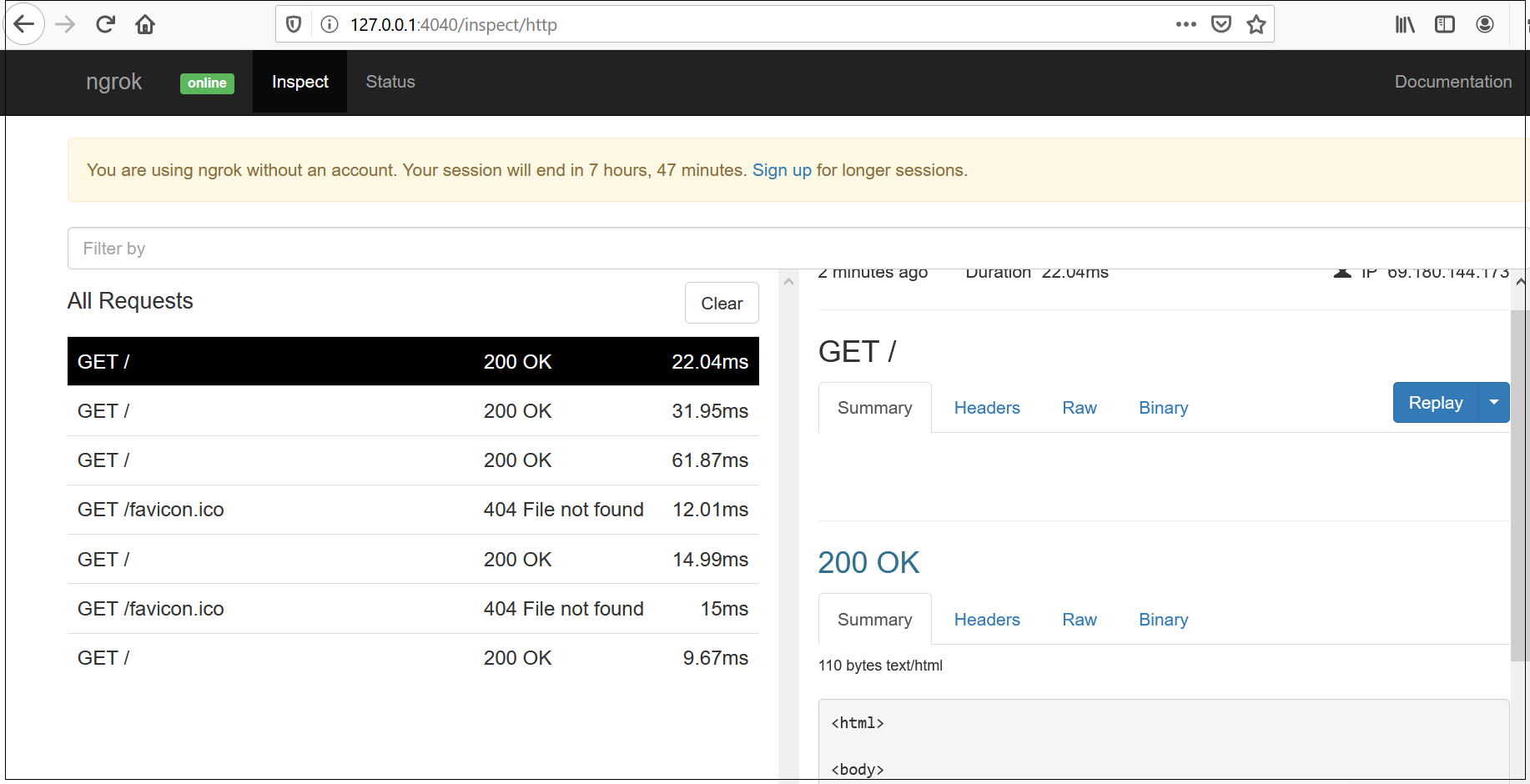
The traffic can be monitored through the following URL — http://127.0.0.1:4040
The ngrok and python HTTP server can be used to share the local files externally without much effort and configurations.